
Entropy
Switching business domains, architecting software systems, platform engineering, or writing clean and maintainable code are all challenging tasks. But they all share a common heuristic we can apply to help tackle these problems: examining these tasks through the lens of entropy.
Here’s what most developers miss about complexity:
It’s wrong to think that writing complex code is complex and writing simple code is simple.
Let me take you on a journey through entropy’s many faces and show you why this counterintuitive truth matters for everyone building software systems. We’ll explore how entropy manifests in code quality, system architecture, data engineering, and machine learning—then discover practical frameworks for applying entropy thinking to your own projects.
What Is Entropy, Really?
In physics, entropy measures disorder—the tendency of systems to move from organized to chaotic states. Your coffee gets cold, never hot. Broken things stay broken. The universe inexorably slides toward maximum entropy.
But entropy isn’t just about physics. This same mathematical concept appears everywhere in technology:
In Information Systems:
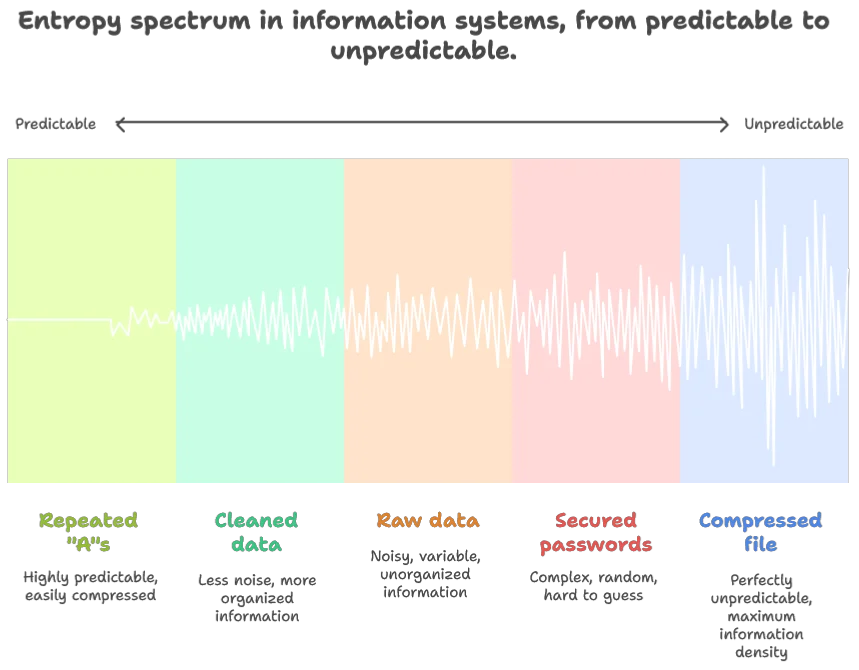
- Information Theory: Measures how dense and unpredictable information can be. A perfectly compressed file has maximum entropy because every bit is unpredictable. A file full of repeated “A”s has low entropy because it’s completely predictable
- Data Engineering: Raw master data contains high entropy with all its noise and variability, while cleaned derived data has lower entropy
- Cybersecurity: From low-entropy legitimate packets to high-entropy secured passwords
In Software Design:
- Code Quality: Well-structured code with clear patterns has low entropy, while chaotic, unmaintainable codebases have high entropy
- System Architecture: Monolithic and microservices architectures differ in where they concentrate versus distribute their complexity and entropy
- Natural Language Processing: Despite appearing inefficient compared to programming languages, natural language’s redundancy and entropy patterns make it remarkably resilient to errors
In Broader Systems:
- Biology: Living systems create local order by increasing entropy elsewhere—we build complexity while generating heat and waste
- Economics: High entropy may reflect the beneficial complexity of incorporating all available information
- Social Systems: Moderate entropy reflects healthy organizational complexity, while too little suggests stagnation and too much indicates chaos
The same mathematical concept describes both cosmic chaos and elegant compression. And this paradox holds the key to understanding better software design.
The Meaning of Life
There’s a compelling theory that life itself exists to accelerate entropy increase—that consciousness and complexity are the universe’s way of more efficiently converting organized energy into heat. While “42” remains the traditional non-answer to life’s meaning, perhaps we’re actually entropy’s servants, building increasingly complex systems that ultimately dissipate energy more effectively.
The Three Faces of Entropy in Code
Understanding Code Entropy
Well-structured code exhibits three distinct types of entropy simultaneously. Understanding these helps us make better design decisions:
Lexical Entropy: Information Density
Definition: The diversity of tokens, identifiers, and vocabulary in your code.
When you apply DRY principles (Don’t Repeat Yourself) and create meaningful abstractions, you’re increasing lexical entropy—every line becomes more information-dense, less predictable from its neighbors. In information theory terms, you’ve made your code more “compressed.”
Example: Compare these two code snippets:
# Low lexical entropy (repetitive)
user_name = request.get('name')
user_email = request.get('email')
user_age = request.get('age')
# High lexical entropy (compressed)
user_data = {field: request.get(field) for field in ['name', 'email', 'age']}Structural Entropy: Organizational Complexity
Definition: The complexity of your code’s organizational patterns and architectural decisions.
Well-architected systems have low structural entropy—they follow predictable patterns, consistent conventions, and clear hierarchies. You can navigate them intuitively because they follow established principles.
Practical Application: Consistent naming conventions, standardized project structure, and predictable module organization all reduce structural entropy.
Semantic Entropy: Conceptual Complexity
Definition: The conceptual complexity and domain diversity within a component.
Good code has low semantic entropy—each component has a clear, single responsibility rather than mixing multiple concerns. When a function handles both user authentication AND file parsing, it has high semantic entropy.
The Sweet Spot: High lexical entropy (expressive, non-redundant) with low structural and semantic entropy (predictable, focused).
Think of it like the difference between a Shakespearean sonnet and white noise. Both have high lexical entropy (unpredictable word choices vs. random data), but the sonnet has low structural entropy (follows poetic patterns) while noise has high structural entropy (no patterns at all).
The Resilience Trade-off
Here’s where entropy theory reveals something profound about system design: high entropy maximizes information density but minimizes resilience.
Think about QR codes—brilliant examples of entropy engineering. The data payload is highly compressed (high entropy), but the entire code includes massive redundancy through error correction. You can damage up to 30% of a QR code and it still works. The designers parameterized this trade-off based on expected “channel quality.”
This pattern appears everywhere:
- TCP vs UDP: TCP adds redundancy (acknowledgments, retransmissions) for reliability, while UDP maximizes efficiency
- DNA: Could be much more compact, but evolution chose redundancy for error correction
- Natural language: We repeat ourselves, use filler words, and gesture—all “inefficient” but crucial for noisy human communication
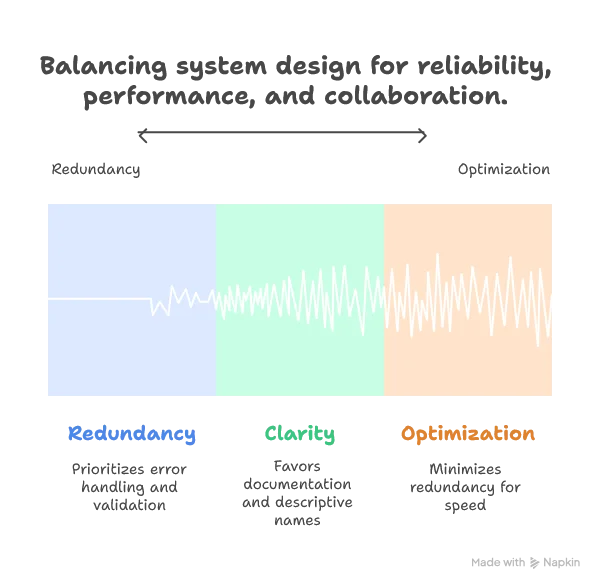
Practical Framework: When designing systems, explicitly choose your entropy-resilience trade-off:
- High-reliability contexts: Add redundancy (error handling, validation, monitoring)
- High-performance contexts: Minimize redundancy (optimized algorithms, compressed data)
- Collaborative contexts: Include “wasteful” clarity (comments, descriptive names, documentation)
Entropy in System Architecture
Essential vs. Accidental Complexity
This brings us to the heart of software design: the difference between essential complexity (inherent to the problem) and accidental complexity (created by poor design).
When we try to force inherently complex systems into overly simple abstractions, we don’t eliminate complexity—we just push it into awkward workarounds and hidden dependencies. The entropy has to go somewhere. It’s like trying to compress an already-compressed file; you often make it larger.
Entropy Archaeology Framework:
The real engineering challenge is what I call entropy archaeology—excavating the true structure of the problem from the noise of implementation decisions. Here’s a practical approach:
- Map Current Entropy: Identify where complexity currently lives in your system
- Classify Complexity: Distinguish essential (domain-required) from accidental (implementation-created)
- Relocate Strategically: Move complexity to where your team can best manage it
- Validate Simplification: Ensure you haven’t just hidden complexity elsewhere
As Michelangelo supposedly said about David: “I didn’t carve the statue, I just removed everything that wasn’t David.”
The Entropy-Capability Principle
Here’s a fundamental truth about system design that most engineers learn the hard way:
The more capabilities you want from your system, the higher the entropy you will require.
Want complex business processes? You need entropy to handle diverse workflows. Want easy deployment? You need entropy to manage different environments. Want feature variety? You need entropy to accommodate diverse requirements.
But here’s the catch: having more entropy than required forces you to handle cases you wish you didn’t have to.
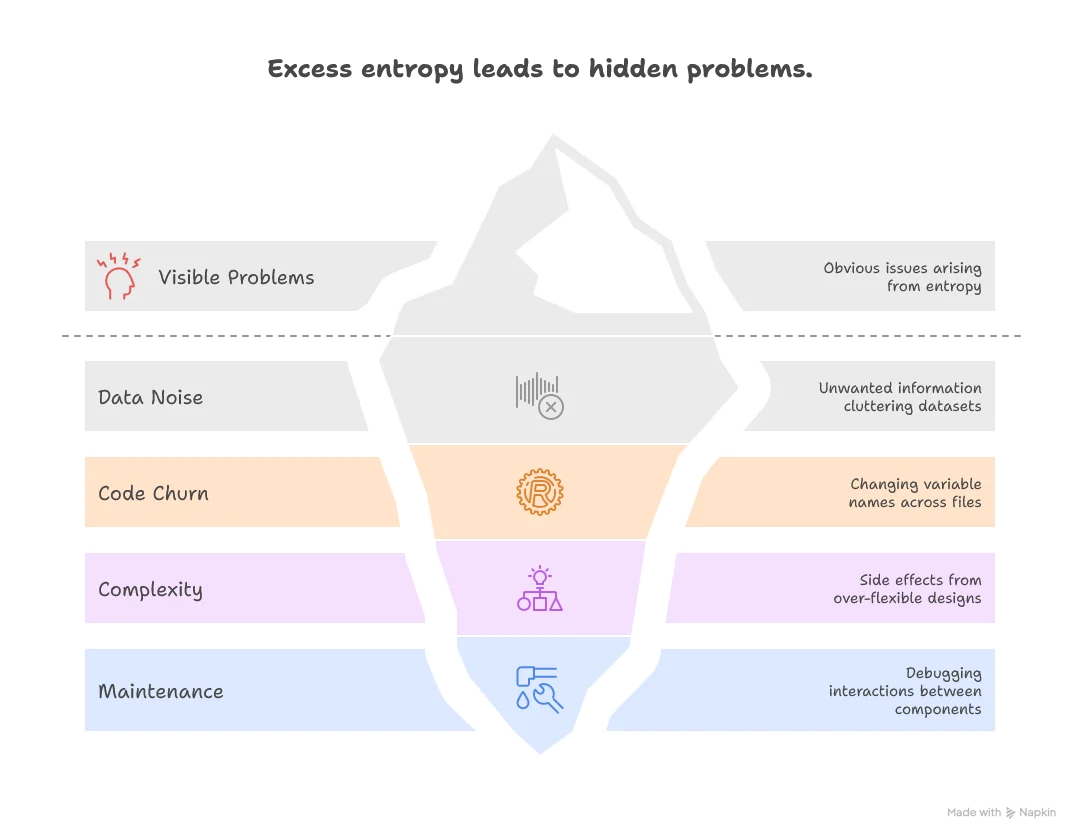
This excess entropy manifests as:
- Data noise: Filtering unwanted information that clutters your clean datasets
- Code churn: Changing variable names across thousands of files when requirements shift
- Unintended complexity: Managing side effects and edge cases that emerge from over-flexible designs
- Maintenance overhead: Debugging interactions between components that shouldn’t interact
With greater entropy comes greater responsibility (and headaches).
This leads to a crucial design principle: Maximize entropy to match requirements, minimize entropy to enhance maintainability.
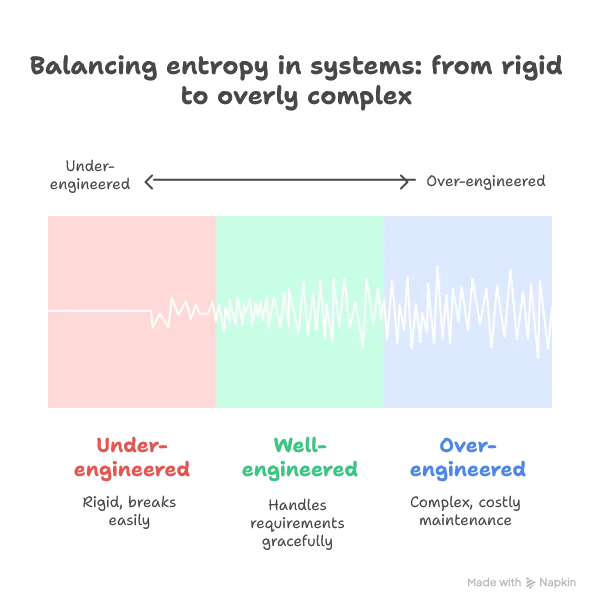
The Goldilocks Zone of System Entropy
The sweet spot lies in having just enough entropy to meet your actual needs:
Finding Your Entropy Sweet Spot
Practical Application
When designing systems, explicitly ask:
- What capabilities do we actually need? (Not what we might need someday)
- What’s the minimum entropy required to deliver those capabilities?
- Where is entropy creeping in that doesn’t serve our requirements?
- How can we contain entropy to preserve maintainability?
The goal isn’t to eliminate entropy—it’s to make every bit of entropy earn its place in your system.
Architectural Entropy Distribution
Let’s examine how different architectural styles manage entropy:
Monolithic Systems: Concentrated Entropy
Monolithic systems concentrate entropy within a single, tightly coupled codebase.
Benefits of concentrated entropy:
- Simplified deployment and operational overhead
- Easier cross-cutting concerns (logging, security, transactions)
- Straightforward debugging and testing in a single process
- Lower latency for inter-component communication
Challenges of concentrated entropy:
- High coupling makes changes risky and unpredictable
- Single point of failure affects the entire system
- Difficult to scale individual components independently
- Technology stack becomes locked-in across all features
Microservices: Distributed Entropy
Microservices architectures distribute entropy across multiple independent services.
Benefits of distributed entropy:
- Independent deployment and scaling of components
- Technology diversity allows choosing the right tool for each job
- Fault isolation prevents cascading failures
- Team autonomy and parallel development
- Clear service boundaries enforce good design practices
Challenges of distributed entropy:
- Network complexity and latency concerns
- Data consistency across service boundaries
- Operational complexity multiplies with service count
- Debugging distributed transactions becomes difficult
- Service versioning and API evolution challenges
Decision Framework: Where Should Your Entropy Live?
Choose your entropy distribution strategy based on:
Entropy Distribution Strategy
Entropy in Data and Machine Learning
The Data Entropy Spectrum
Raw vs. Derived Data: The Fundamental Tension
Every data system faces this core trade-off:
Raw Data (High Entropy):
- Maximum information content but chaotic and unusable
- Irreplaceable source of truth
- Requires significant processing for business value
Derived Data (Lower Entropy):
- Structured and actionable but lossy
- Replaceable through reprocessing
- Optimized for specific use cases
Data Processing as Entropy Management:
Effective data architecture consciously manages this entropy transformation:
- Preserve Raw Truth: Keep high-entropy sources intact
- Create Purposeful Views: Derive lower-entropy datasets for specific needs
- Document Transformations: Make entropy reduction steps explicit and reversible
- Balance Granularity: Retain enough detail for future unknown requirements
The Data Entropy Sweet Spot
Too Low Entropy (Brittle Systems):
- Over-aggregated data loses essential nuance
- New business cases become impossible to support
- System lacks adaptability to changing requirements
Too High Entropy (Chaotic Systems):
- Inconsistent data creates confusion and errors
- Multiple conflicting sources of truth
- Maintenance becomes overwhelming
Optimal Entropy (Manageable Complexity):
- Sufficient detail for current and anticipated future needs
- Clear data lineage and consistency guarantees
- Maintainable processing pipelines
Machine Learning: Entropy Optimization
Training data requires sophisticated entropy engineering:
Beneficial High Entropy:
- Lexical diversity and topical breadth in text data
- Varied patterns and edge cases in training examples
- Representative distribution of real-world scenarios
Harmful High Entropy:
- Random noise and measurement errors
- Inconsistent facts and contradictory labels
- Irrelevant variations that confuse model learning
Practical ML Entropy Guidelines:
- Maximize Signal Entropy: Include diverse, representative examples
- Minimize Noise Entropy: Clean inconsistent labels and measurement errors
- Balance Data Entropy: Ensure no single pattern dominates the dataset
- Validate Entropy Distribution: Check that test data entropy matches production
Practical Entropy Engineering
The Art of Optimal Entropy
So what’s the takeaway for software engineers and data professionals?
Perfect efficiency is perfectly fragile. The universe seems to prefer “good enough and robust” over “theoretically optimal but brittle.” Your code should too.
Different contexts demand different entropy profiles:
- Compression algorithms: Want maximum entropy
- Monitoring systems: Want predictable patterns
- User interfaces: Want just enough complexity to solve the problem without overwhelming users
- APIs: Want consistency (low entropy) in structure, expressiveness (high entropy) in capability
The hardest part isn’t writing working code—it’s simplifying it afterward. As Antoine de Saint-Exupéry wrote: “Perfection is achieved not when there is nothing more to add, but when there is nothing more to take away.” This refinement process is where the real engineering happens.
Entropy Engineering Toolkit
Design Questions Framework
Instead of asking “How can I make this simpler?” ask:
- Where should complexity live? (What component can best handle it?)
- Where should I invest in redundancy? (What failures would be catastrophic?)
- What entropy type am I dealing with? (Essential vs. accidental complexity?)
- Who will maintain this entropy? (Does the team have the right skills?)
Entropy Archaeology Checklist
When refactoring existing systems, apply the entropy archaeology checklist:
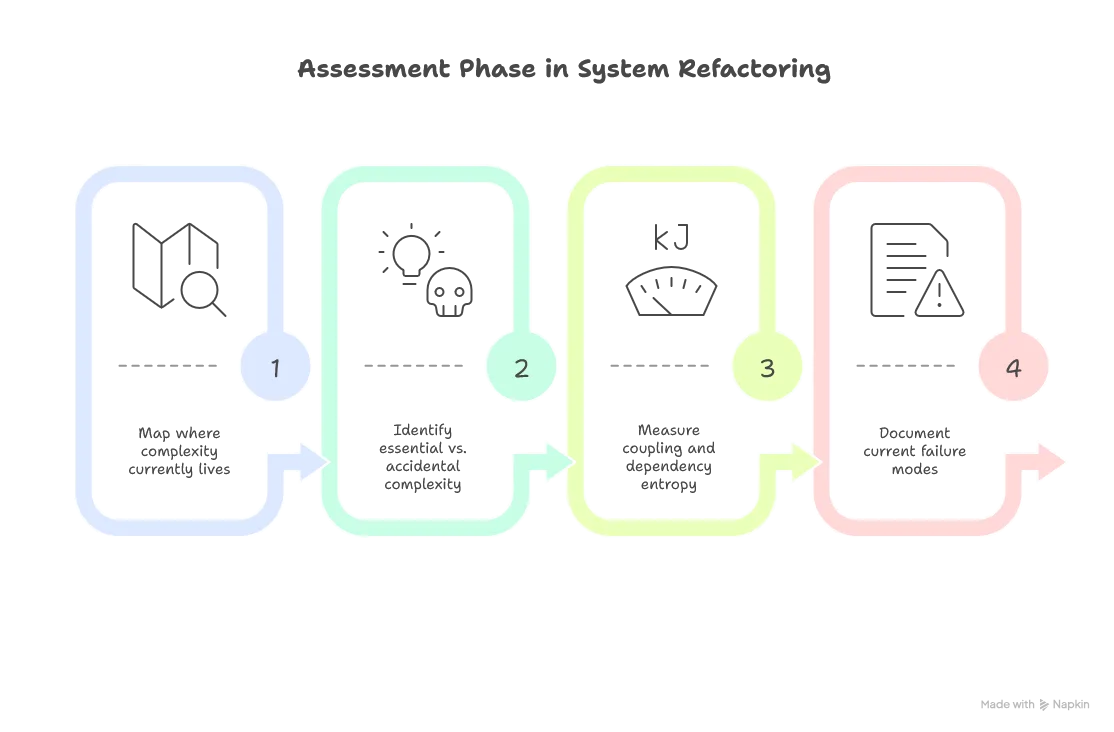
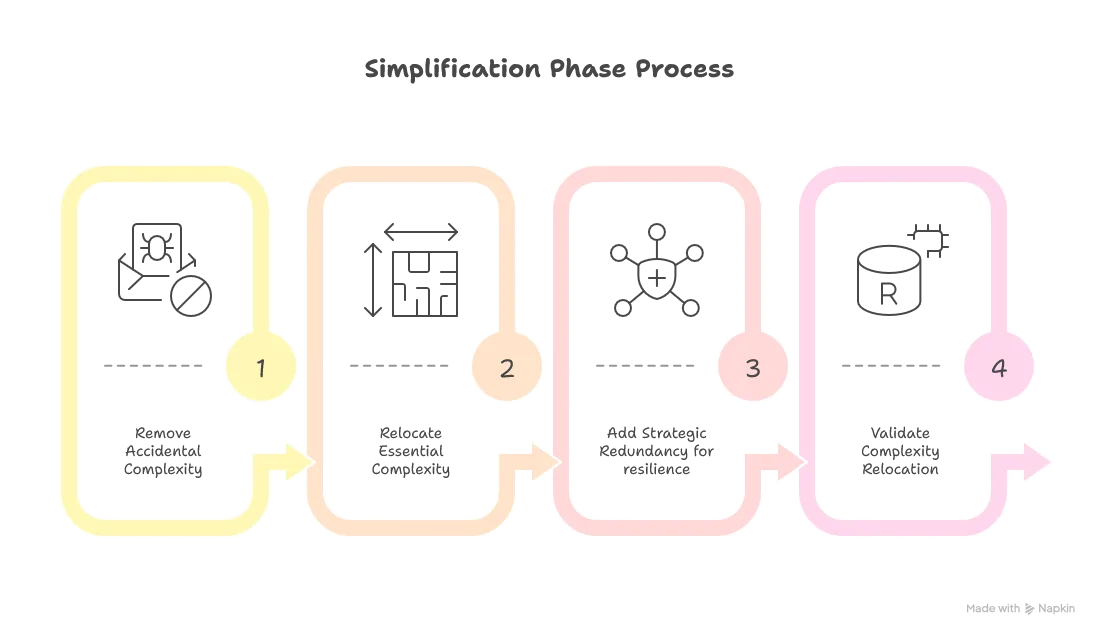
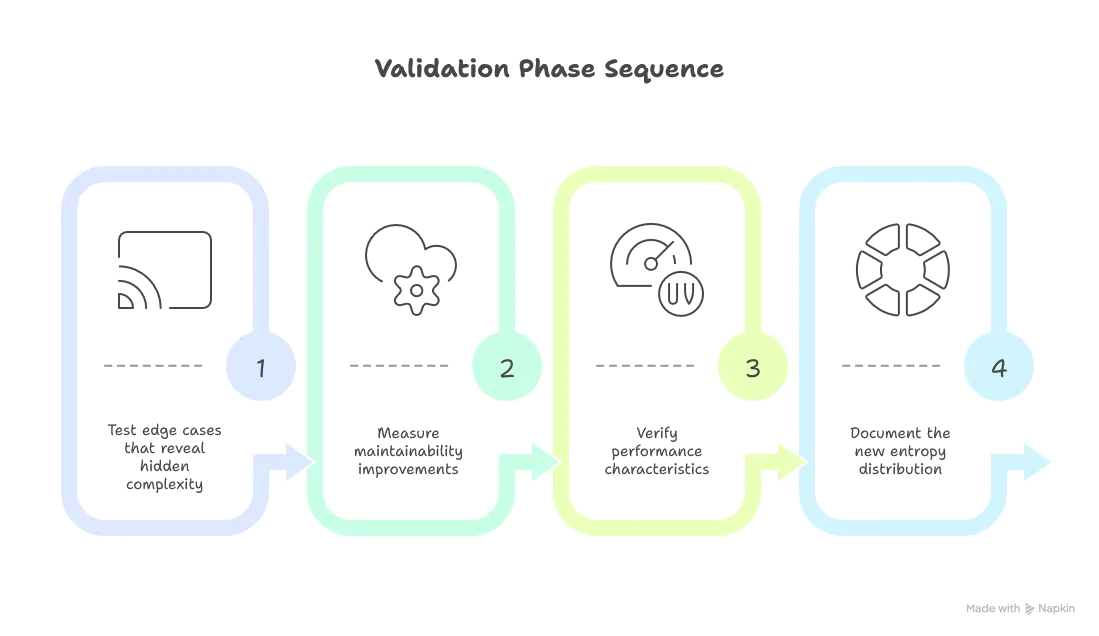
Common Entropy Anti-Patterns
The Compression Fallacy: Believing that shorter code is always better
- Solution: Optimize for appropriate entropy type (lexical vs. structural vs. semantic)
The Distribution Illusion: Moving complexity without reducing it
- Solution: Explicitly track where complexity goes during refactoring
The Premature Optimization: Reducing entropy before understanding the problem
- Solution: Use entropy archaeology to understand current state first
Entropy as Design Philosophy
Thinking about entropy changes how you approach system design fundamentally. Some complexity is essential—it reflects the real structure of your problem domain. Fighting it creates accidental complexity elsewhere. Some redundancy is valuable—it makes systems robust to change and easier to understand.
The best systems aren’t the most compressed or the most redundant. They’re the ones where entropy is distributed thoughtfully, where complexity serves purpose, and where simplicity emerges from deep understanding rather than wishful thinking.
Good engineering is entropy engineering—consciously designing where information should be dense, where patterns should emerge, and where a little “waste” creates anti-fragility.
The universe may be sliding toward maximum entropy, but that doesn’t mean your codebase has to. Choose your complexity wisely.
Your Next Steps
Ready to apply entropy thinking to your projects? Start here:
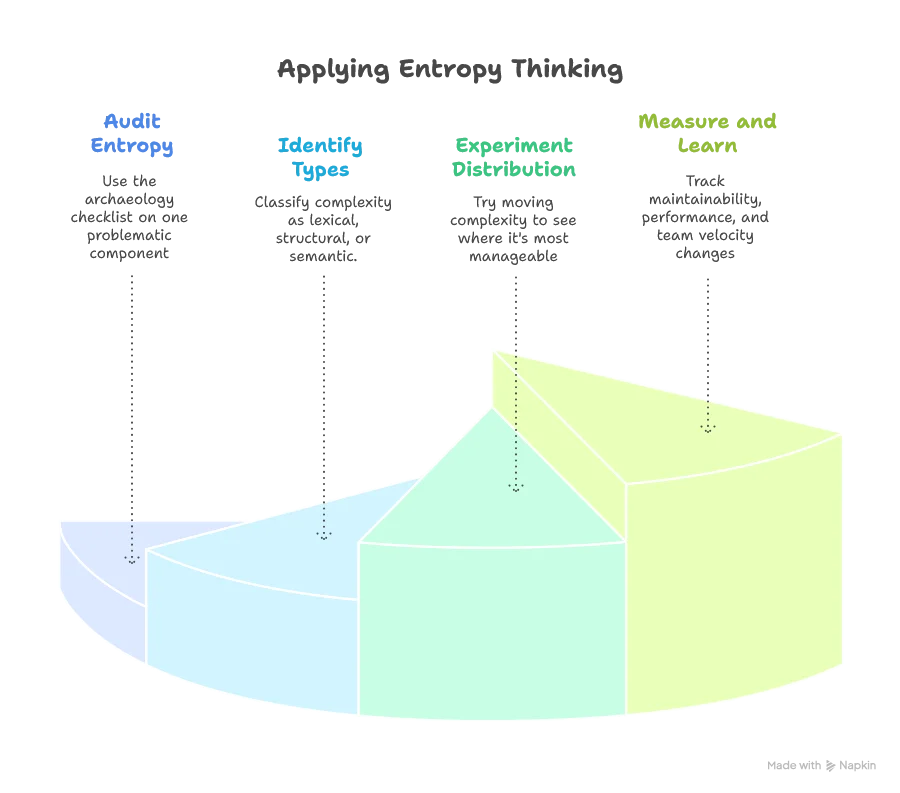
Discussion Questions for Your Team:
- Where does complexity live in our current architecture, and is that optimal?
- What trade-offs are we making between efficiency and resilience?
- How do we distinguish essential from accidental complexity in our domain?
Entropy in Testing: The Hidden Dimension
Unit Testing as Entropy Management
Here’s a perspective that might surprise you: your test suite is an entropy system that mirrors your codebase’s complexity. And just like with system architecture, the key isn’t maximizing or minimizing tests—it’s distributing testing entropy optimally.
The Testing Entropy Spectrum
Too Low Testing Entropy (Under-tested System):
When you have too few unit tests with poor coverage, you’re creating a system with dangerously low testing entropy:
- Insufficient non-regression protection: Changes break existing functionality without warning
- Poor documentation: Tests serve as executable documentation—too few tests mean unclear behavior expectations
- High deployment risk: Lack of confidence makes releases stressful and infrequent
- Technical debt accumulation: Without test coverage, refactoring becomes risky, encouraging workarounds. As Michael Feathers defines it, legacy code is simply code without tests
Too High Testing Entropy (Over-tested System):
But excessive testing creates its own entropy problems:
- Redundant test coverage: Multiple tests covering the same functionality create maintenance overhead
- Brittle test coupling: A single code change forces updates to dozens of tests, drastically reducing developer velocity
- Noise over signal: Important test failures get lost in a sea of broken tests
- False confidence: Passing tests that don’t actually validate meaningful behavior
Testing Entropy Distribution: Scope Matters
The entropy lens reveals why test scope distribution is crucial:
High-Entropy, Narrow-Scope Tests (Unit Tests):
- High precision: Can be very specific about expected results
- Fast feedback: Quick to run and pinpoint failures
- Focused coverage: Test single functions or small components
- High count tolerance: Many narrow tests are manageable because they’re isolated
Lower-Entropy, Broad-Scope Tests (Integration/E2E Tests):
- Relaxed assertions: Focus on overall behavior rather than precise outputs
- Slower feedback: Take longer to run but catch interaction issues
- Broad coverage: Test entire workflows and system integration
- Low count preference: Few broad tests to avoid maintenance explosion
Practical Testing Entropy Guidelines
Entropy-Conscious Test Design:
- Match assertion precision to test scope: Narrow tests can be picky, broad tests should be forgiving
- Distribute entropy across the pyramid: Many specific tests at the base, few general tests at the top
- Avoid entropy redundancy: Don’t test the same behavior at multiple levels with the same precision
- Manage coupling entropy: Tests should be coupled to behavior, not implementation details
Red Flags for Testing Entropy Problems:
- Entropy explosion: Every small code change breaks dozens of tests
- Entropy deficit: Bugs regularly slip through to production
- Entropy mismatch: Integration tests that assert exact string matches or unit tests that ignore specific behaviors
- Entropy redundancy: Multiple test levels validating identical scenarios with identical precision
The Testing Maintenance Principle
Just as with system architecture, the goal is to put testing entropy where your team can best manage it:
- High-entropy unit tests: Easy to maintain because they’re isolated and focused
- Medium-entropy integration tests: Moderate maintenance burden for critical interaction coverage
- Low-entropy E2E tests: High maintenance cost, so use sparingly for the most critical paths
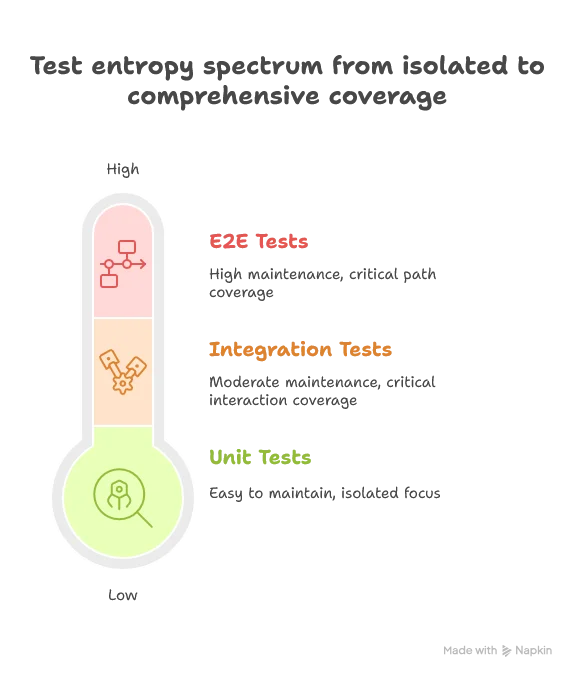
Testing entropy archaeology applies here too: when your test suite becomes unmaintainable, map where the entropy lives, identify what’s essential vs. accidental, and redistribute accordingly.
The best test suites aren’t the most comprehensive or the most minimal—they’re the ones where testing entropy is distributed thoughtfully to maximize confidence while minimizing maintenance burden.
What’s your experience with the complexity-simplicity trade-off in your projects? Have you found examples where embracing complexity led to better outcomes? Share your thoughts—entropy is fascinating precisely because it shows up everywhere once you start looking.
...fferent information serves different purposes at different times. In a way, it's a strategy against entropy — the natural tendency of information systems to decay into disorder. The delta engine...
.... You cannot avoid the necessary coordination entropy; fighting against it makes things worse. (See my entropy article if this topic interests you.)