
The Eight Saga Patterns
Prelude
This article is heavily based on two fantastic books:
- Software Architecture, the hard parts, by Neal Ford, Mark Richards, Pramod Sadalage and Zhamak Dehghani
- Designing Data-Intensive Applications, by Martin Kleppmann
Both books tackle distributed transactions brilliantly—the former through an engineering lens, the latter from a more academic perspective. What makes this article unique is how we’ll bridge these two worlds, building rock-solid fundamentals that you can actually apply to real systems.
Recap: The saga fundamentals
In the previous article, we explored the theoretical foundations of distributed transactions. We dissected ACID properties with newfound nuance, understanding that atomicity, consistency, isolation, and durability each play distinct roles. We introduced BASE as an alternative philosophy for distributed systems. We examined XA transactions and their 2PC protocol, understanding both their power and their significant limitations.
Most importantly, we established that sagas operate across three dimensions:
- Communication: Synchronous (REST-like) vs. Asynchronous (messaging-based)
- Coordination: Orchestration (centralized control) vs. Choreography (distributed coordination)
- Consistency: Atomic (all-or-nothing) vs. Eventual (temporarily inconsistent but eventually correct)
With 2 × 2 × 2 combinations, we have eight possible saga patterns. But which ones actually work in practice? Which ones scale? Which ones should you avoid at all costs?
Let’s find out.
The eight saga patterns
The Commit Esports CTO stands at the whiteboard, marker in hand. “So we have three dimensions,” he says, drawing three axes. “Communication: sync or async. Coordination: orchestration or choreography. Consistency: atomic or eventual. That gives us…” he pauses, calculating, “…eight possible combinations.”
The lead architect nods slowly. “Not all of them will be practical, though.”
“Exactly,” the CTO agrees. “But understanding all eight helps us see why some patterns work better than others. Let’s explore each one.”
What follows is Mark Richards and Neal Ford’s saga taxonomy—a systematic exploration of every possible combination. Each pattern has earned a memorable name that captures its essential character.
To keep this exploration concrete and focused, we make several simplifying assumptions:
- Synchronous communication uses REST-style HTTP endpoints.
- Asynchronous communication uses messaging with a message broker (e.g., RabbitMQ, Kafka).
- No gRPC: We exclude gRPC from our examples for simplicity, though it could be used in practice.
- Consistency definitions: While these eight sagas draw heavily from Mark Richards and Neal Ford’s taxonomy, we define the consistency dimension more rigorously based on Martin Kleppmann’s treatment:
- Atomic: All participants agree to commit the transaction or all agree to abort it (ACID-style atomicity).
- Eventual: Individual services may temporarily show partial transaction results that could later be compensated or rolled back.
- Atomicity implementation: Multiple strategies exist for achieving atomicity in distributed systems (two-phase commit, three-phase commit, consensus algorithms, Google TrueTime). We’ll focus on the most straightforward: two-phase commit (2PC).
These conventions trade some real-world complexity for clarity. In production systems, you’ll encounter hybrid approaches and additional patterns beyond what we cover here.
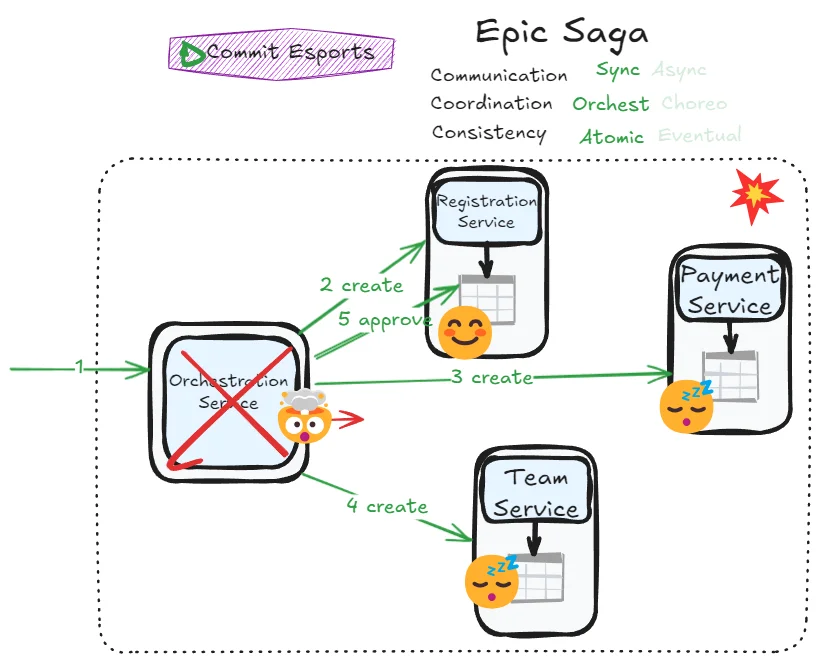
Epic Saga
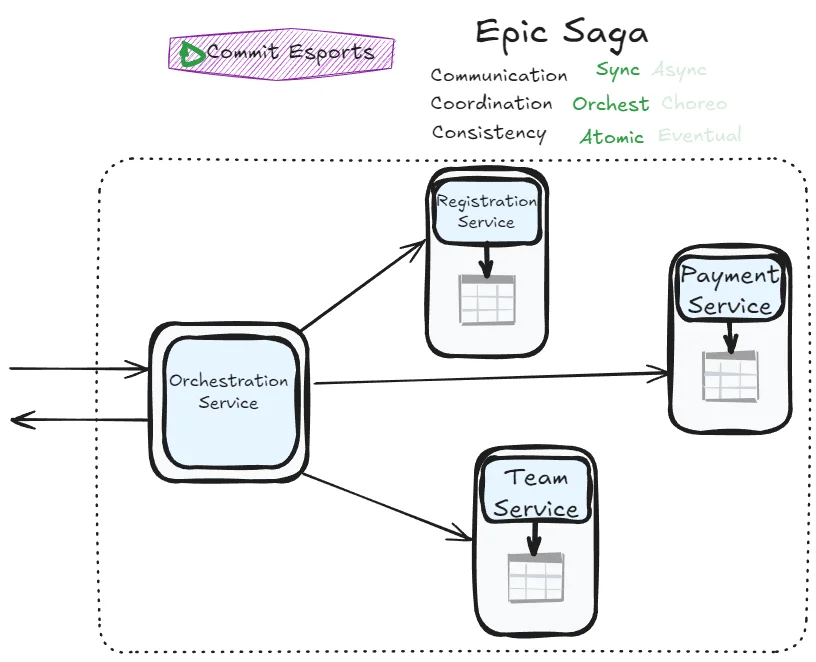
As we discussed earlier, achieving atomicity requires implementing a two-phase commit (2PC) approach. The orchestrator service manages the entire transaction by asking each participant if they’re ready to commit (prepare phase), then instructing all participants to either commit or abort based on their responses.
A successful scenario looks like this:
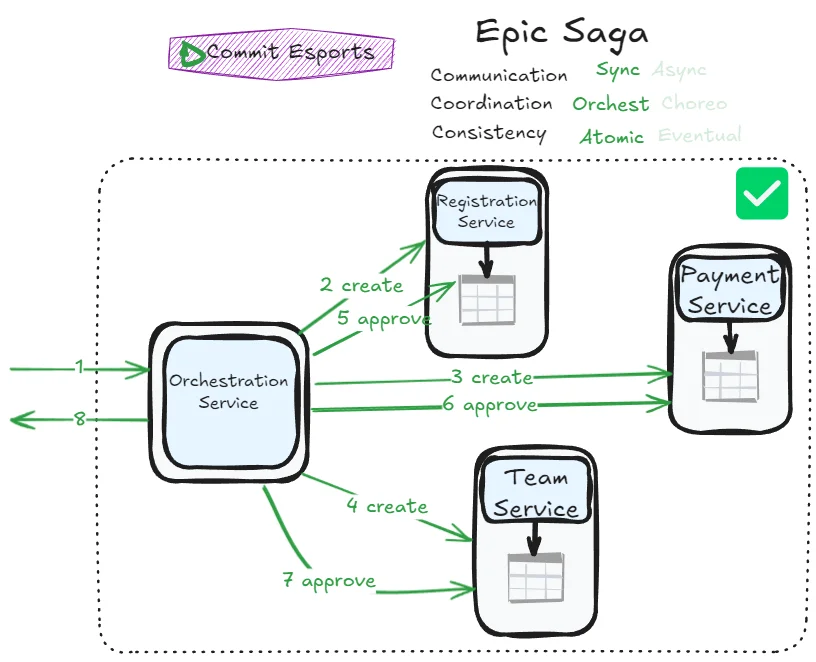
A common implementation strategy uses state management—each table adds a state column tracking the current status of rows involved in the transaction. States might progress from PENDING to COMPLETED.
But wait… doesn’t this flow look familiar?
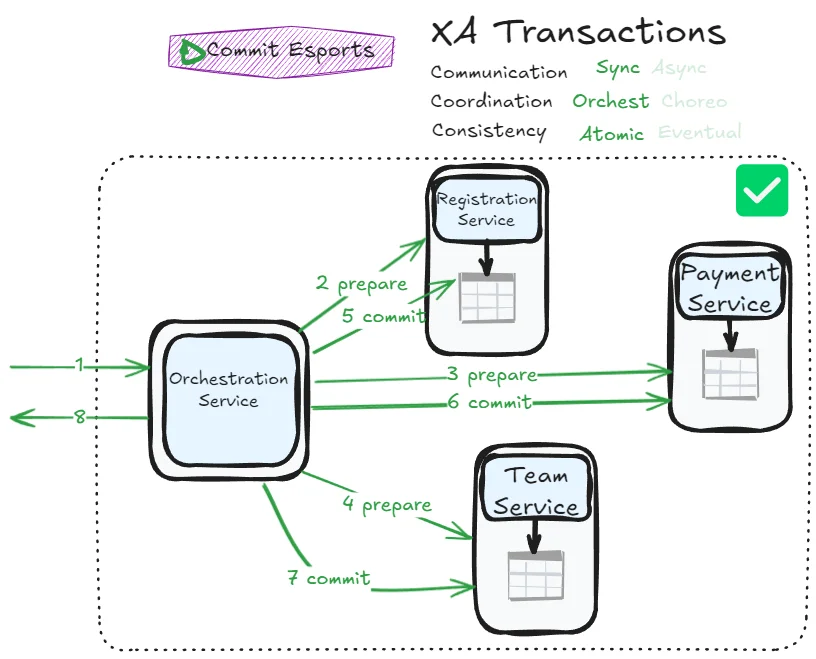
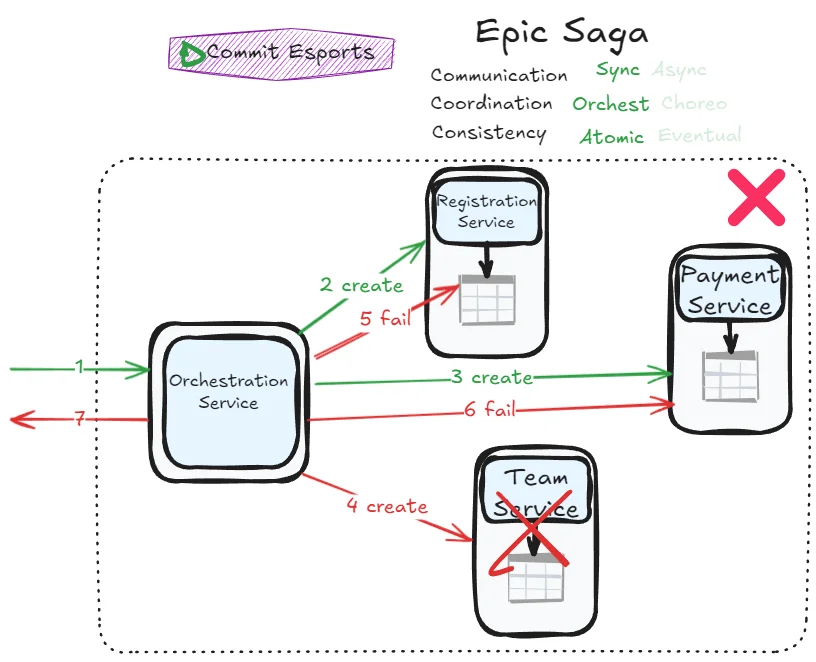
That’s right—this is essentially the same pattern as XA transactions, as seen in previous post! The failure scenarios also mirror each other:
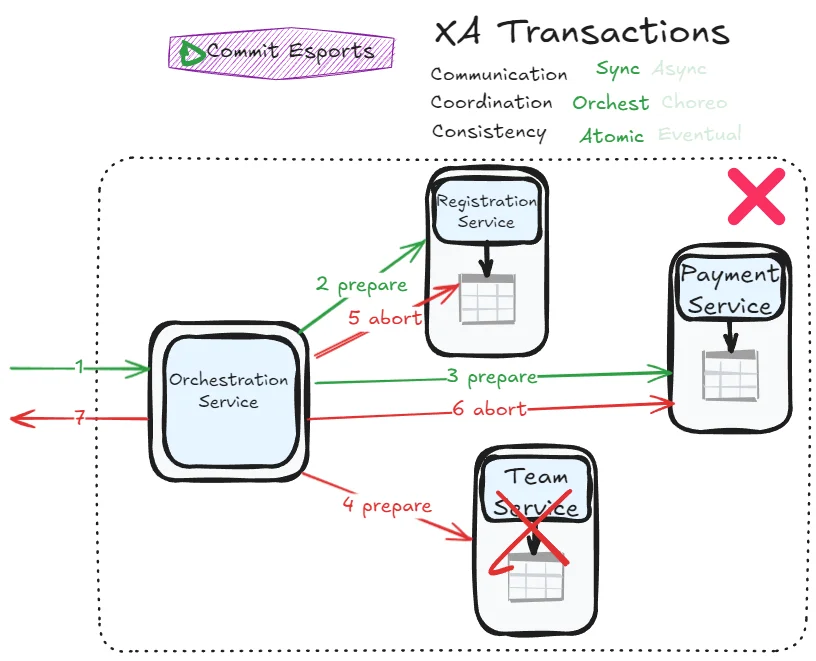
Sagas are often presented as the alternative to XA transactions. The truth is more nuanced: Epic Sagas and XA are close relatives.
The key difference: Epic Sagas implement two-phase commit at the application level, while XA implements it at the database/message broker level. XA can maintain additional guarantees like consistent secondary indexes. Epic Sagas break the abstraction layer (adding state columns, for example) but gain compatibility with participants that don’t support XA protocols.
Pros:
- Low logical complexity—the pattern is straightforward to understand
- Strong consistency guarantees
Cons:
- High coupling:
- Direct synchronous communication between services
- Central mediator creates a dependency point
- Atomic scope spans all participants globally
- Limited responsiveness and scalability:
- Mediator becomes a bottleneck
- Atomicity requires additional coordination steps
- Synchronous communication blocks other operations
- Operational complexity: Mediator failure impacts the entire system
When to use XA transactions:
- Consistency is paramount and you need database-level guarantees (like consistent secondary indexes)
- All participants are XA-compliant
When to use Epic Sagas:
- You want to minimize lock duration
- Some participants don’t support XA protocols
- You need more control over the coordination logic
Fantasy Fiction Saga
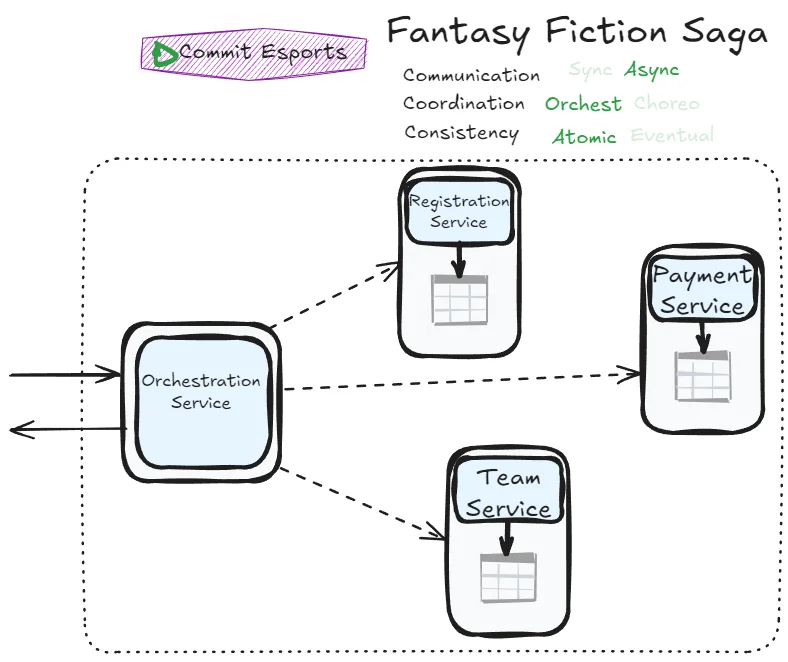
We’re attempting to achieve atomicity with asynchronous communication—implementing 2PC through a message broker. The logical flow becomes significantly more complex:
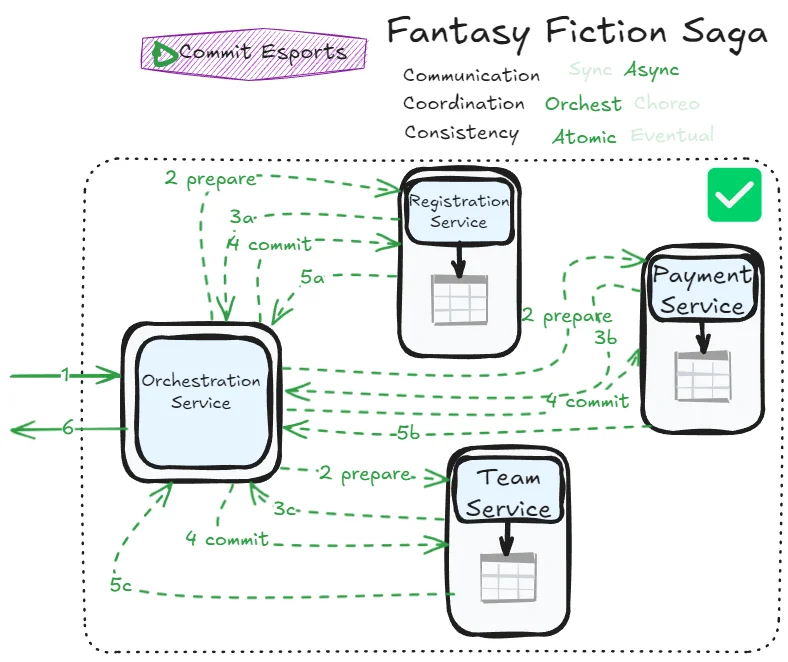
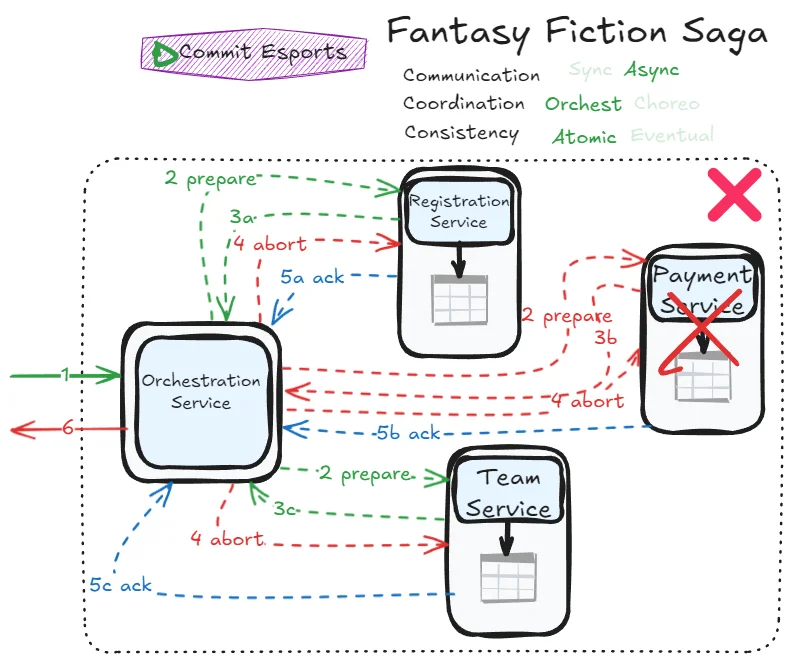
The fundamental problem with achieving atomicity through non-blocking workflows is that the orchestrator must manage multiple concurrent transactions, each requiring multiple coordination steps.
The asynchronous nature creates a dangerous feedback loop: while responsiveness appears enhanced initially, you’re actually allowing more transactions to pile up simultaneously. This increases the orchestrator’s load, which leads to more row locks, which slows down subsequent transactions, which causes even more transactions to queue up. The number of possible failure scenarios explodes due to workflow complexity and increased transaction volume, making this pattern extremely challenging to implement reliably.
Pros:
- Strong consistency guarantees (in theory)
Cons:
- Coupling: Central mediator creates dependencies
- Complexity explosion: Managing distributed atomic transactions asynchronously is extraordinarily difficult—the mediator must coordinate multiple atomic commits simultaneously, causing error-handling complexity to grow exponentially
- Performance degradation: Making distributed atomic transactions non-blocking paradoxically worsens performance—it increases pending transaction count, slowing resolution even further
This pattern is rarely seen in production systems for good reason. The complexity typically outweighs any theoretical benefits.
Fairy Tale Saga
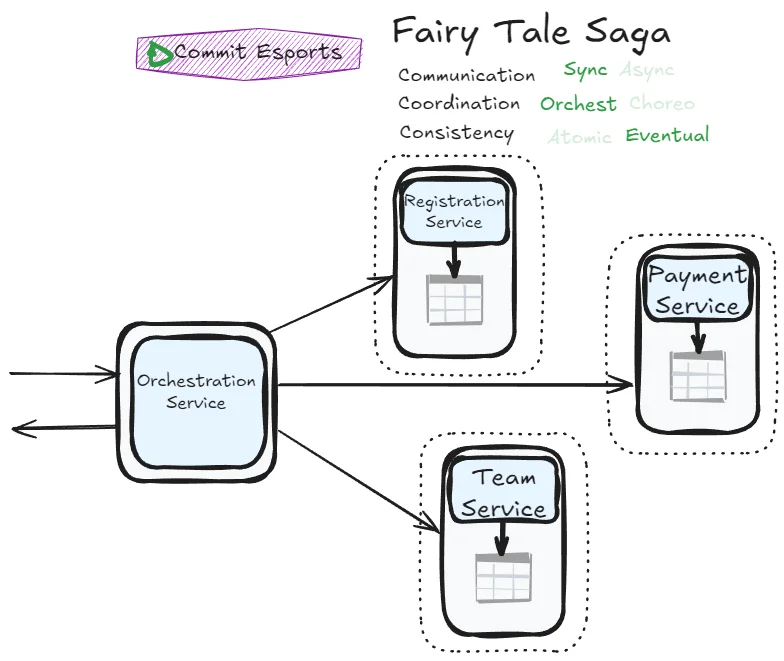
Let’s return to synchronous communication while relaxing the atomicity constraint. This is where sagas start becoming practical.
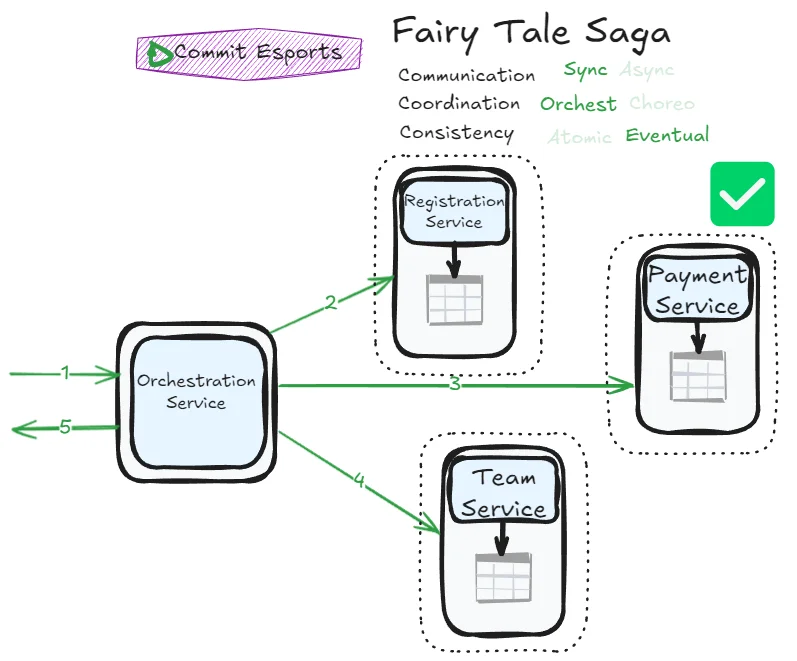
This is arguably the simplest saga pattern to implement successfully. Error management complexity is elegantly handled by the orchestrator. Synchronous communication provides immediate feedback, enabling a more stateless implementation.
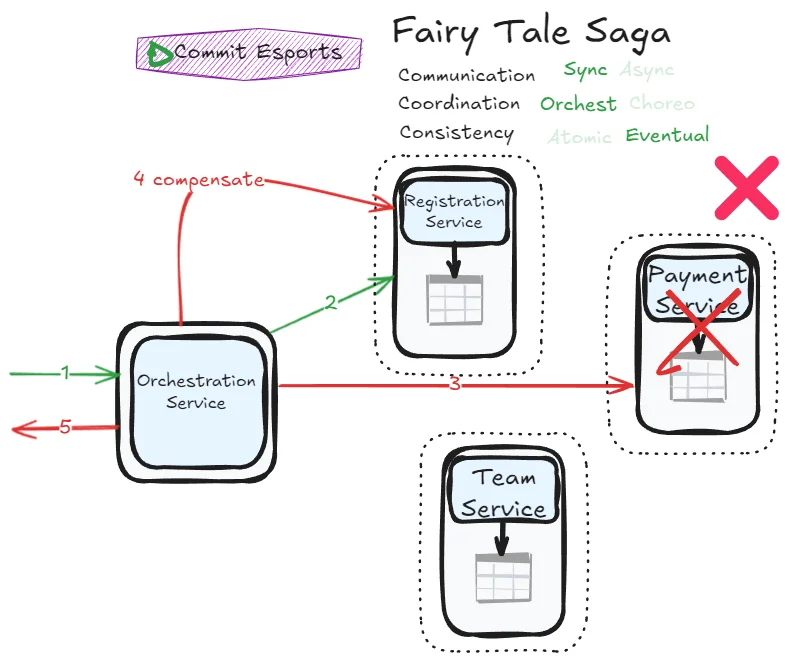
We accept that services may temporarily show inconsistent data by scoping transactions at the service level. However, the synchronous nature ensures we can correct inconsistencies as quickly as possible using either state management (tracking transaction progress) or compensating transactions (undoing completed steps).
Pros:
- Simplest saga implementation:
- Error handling simplified through central orchestrator
- No distributed atomic transactions to coordinate
- Synchronous communication helps keep transaction state manageable
- Easily scalable: Eventual consistency and synchronous patterns scale well together
Cons:
- Coupling:
- Synchronous communication creates service dependencies
- Central mediator required
- Eventual consistency: Temporary inconsistencies are visible to users
This is often the first saga pattern teams implement when migrating from monoliths. It provides a good balance of simplicity and capability.
Parallel Saga
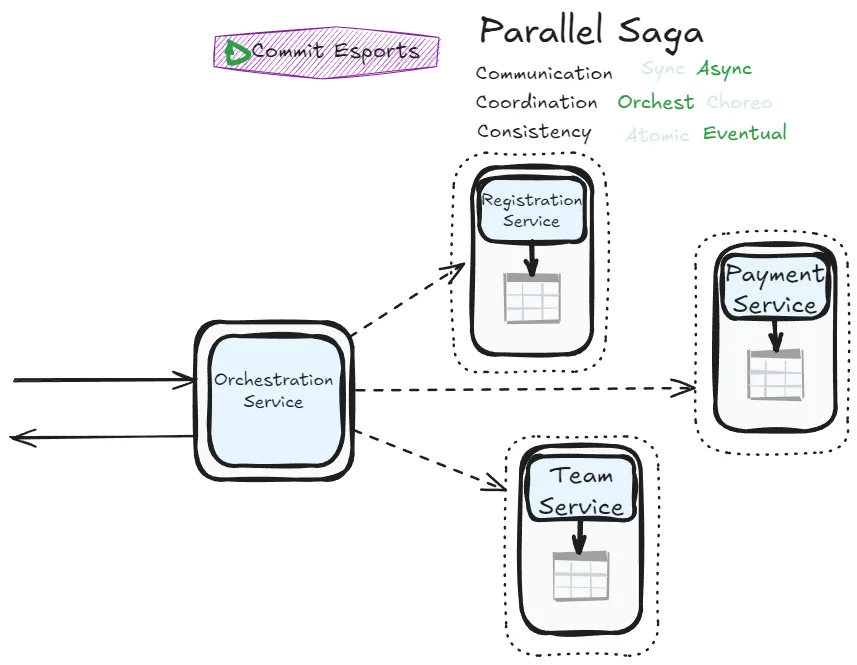
The Fairy Tale Saga works well—why not decouple services further by switching to asynchronous communication?
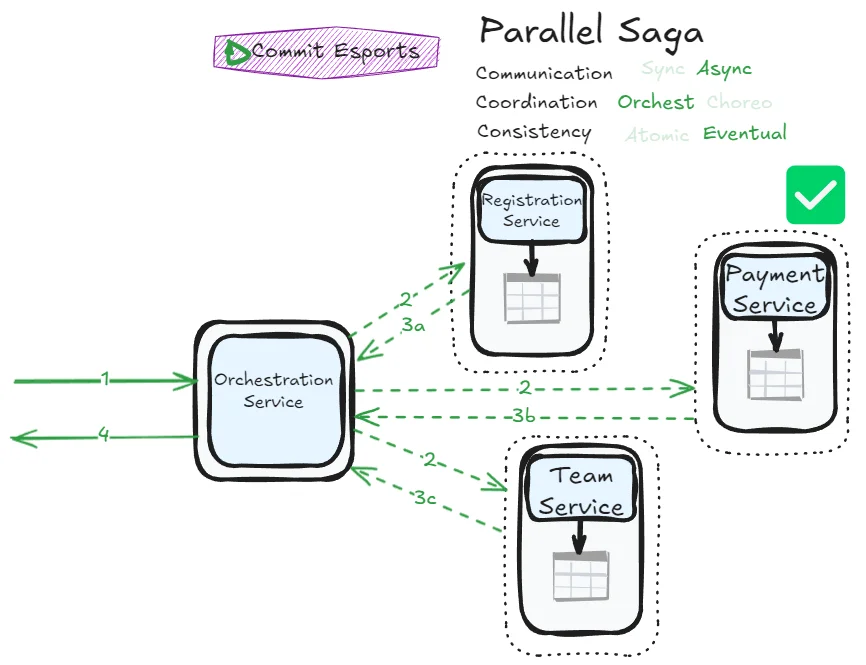
Response after all services confirmed the transaction
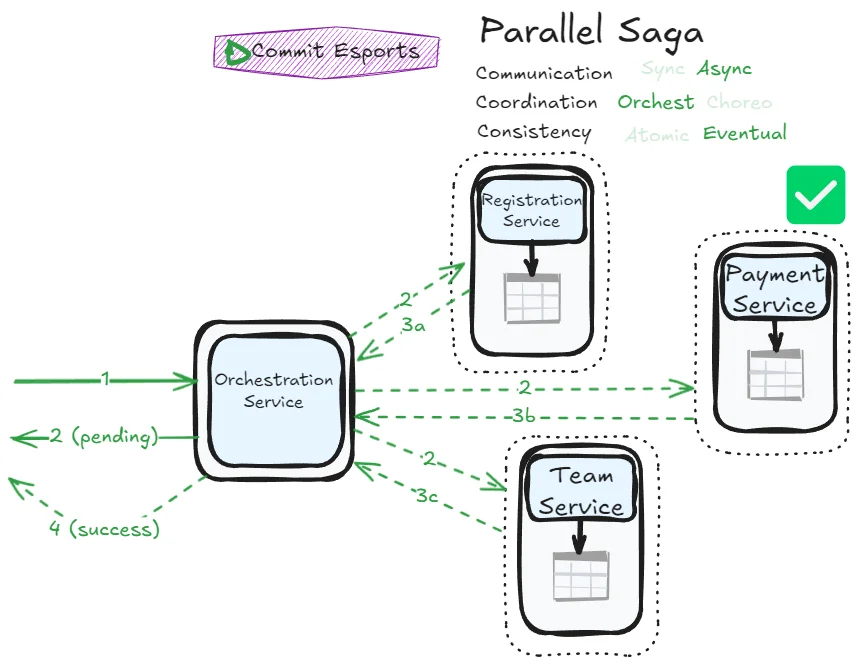
Response immediately and confirmation later
Note: Actually, the possibility to answer to the user request immediately or later on asynchronously can be implemented with ALL asynchronous sagas. For the sake of simplicity, we only show this distinction with this particular saga.
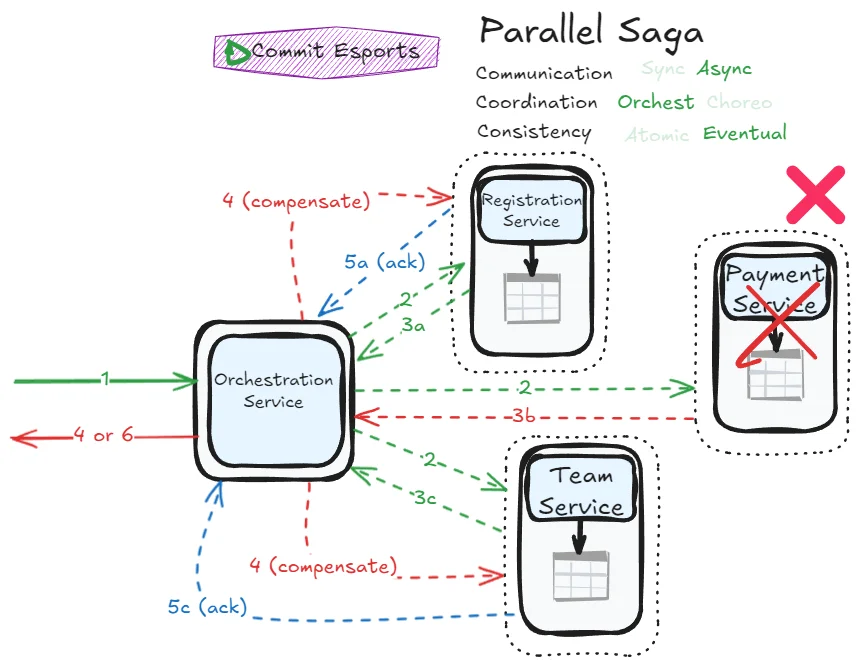
Response after all services confirmed the transaction
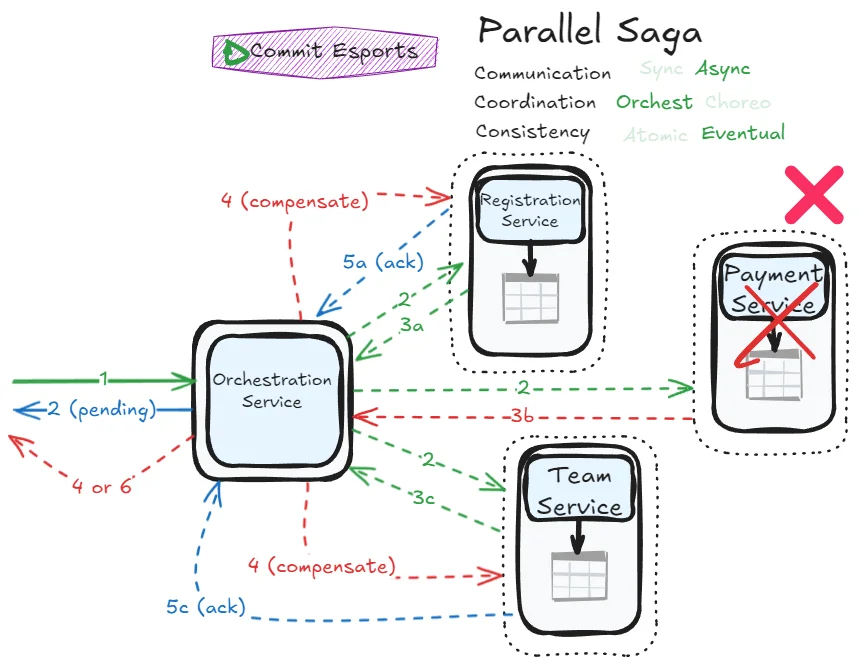
Response immediately and failure notification later
Note: Again, this distinction is actually possible with all asynchronous sagas.
Error management flows become more complex, but this saga achieves impressive responsiveness. You can immediately confirm to users that their request is being orchestrated (returning a “pending” status) and notify them later when processing completes. The asynchronous nature allows the orchestrator to contact all participants without blocking, potentially making the overall process faster.
Pros:
- Lower coupling:
- Message broker decouples services from direct dependencies
- Transactions scoped at the service level
- Highly responsive:
- Fire-and-forget nature enables fast user feedback
- No global atomicity coordination required
Cons:
- Error handling complexity: Asynchronous nature makes failure scenarios harder to manage
- Eventual consistency: Temporary inconsistencies are visible
This pattern excels when user experience demands fast response times, and you can afford to handle compensation asynchronously.
Phone Tag Saga
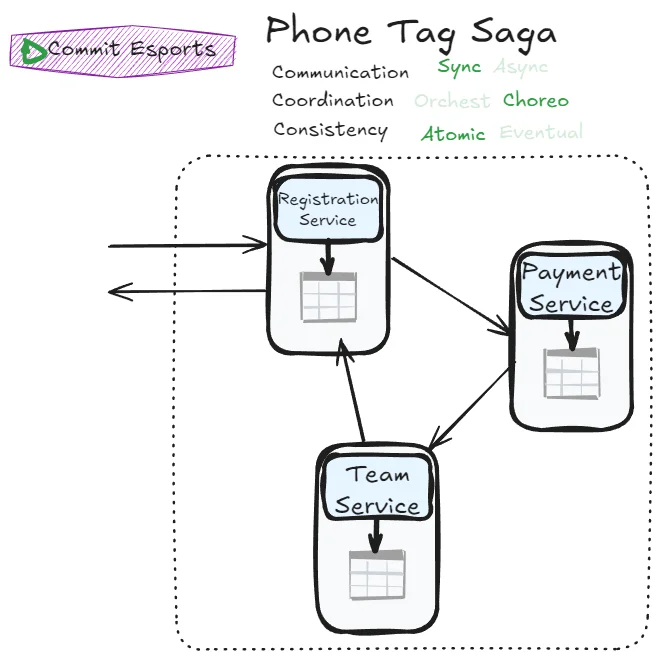
Can we achieve atomicity without an orchestrator? Let’s try:
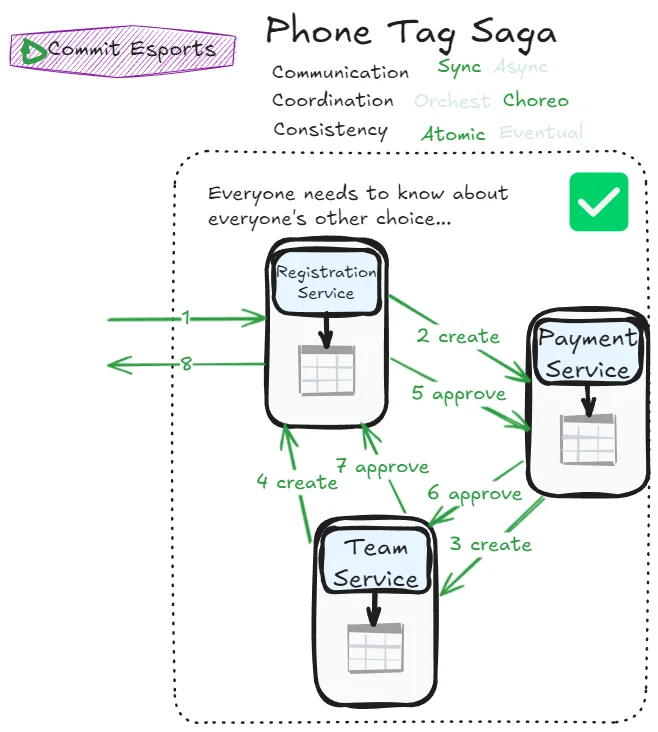
This pattern forces many back-and-forth calls between each participants. Without a clear orchestrator, every participant should know about every other participants’ decision to know if they can commit or should abort. This is counterproductive: we try to achieve a better autonomy using choreography but end up in a coupled system anyway with a more complex workflow management. Is this pattern just unusable?
Not mentioned in Mark Richard and Neal Ford’s book, it can be interesting to push the thoughts a bit further. What if we have a disguised mediator: one of the service acts as a mediator but this mediator’s role could be anyone?
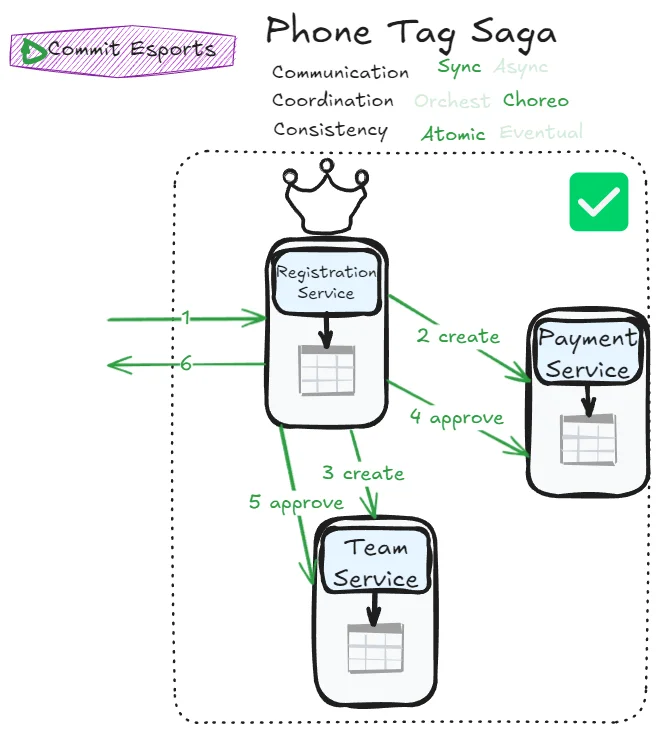
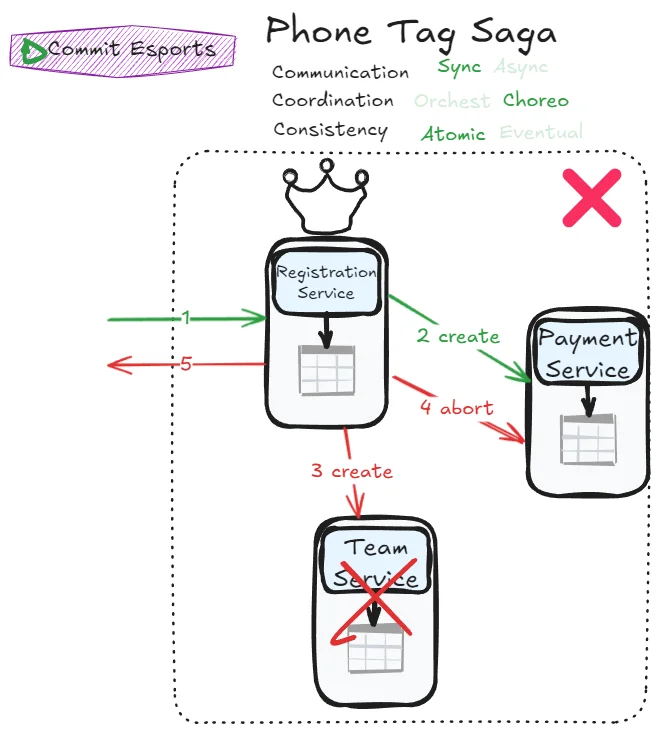
We can already observe a small win: flows are simpler. Coupling is more explicit, which paradoxically reduces slightly actual coupling: payment service no longer needs to know team service’s existence and vice-versa.
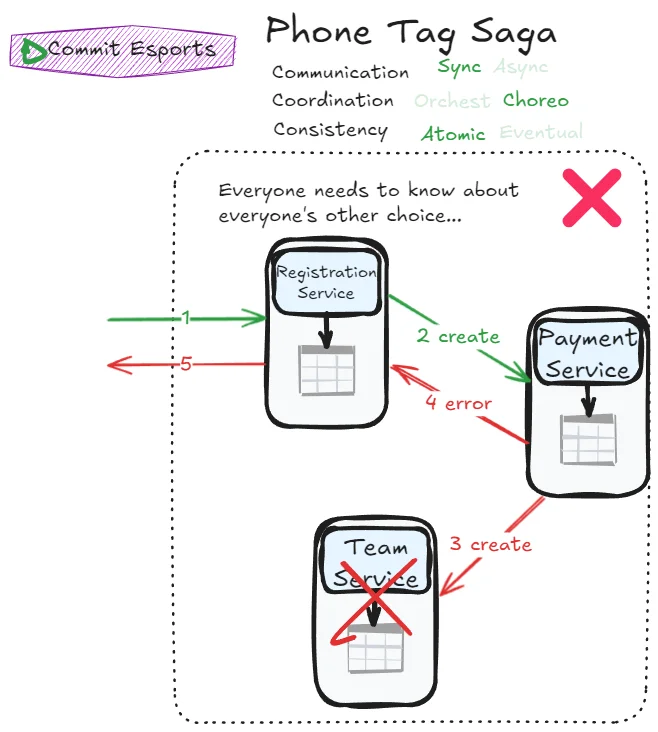
Still, we’re just imitating an Epic saga transaction so far. Benefits become clearer when evaluating what could happen if the mediator goes down in the middle of the transaction:
In the Epic saga, even if everyone agreed to the transaction, we are stuck until the mediator is back and finishes the transaction. Observe what a Phone Tag saga can unlock:
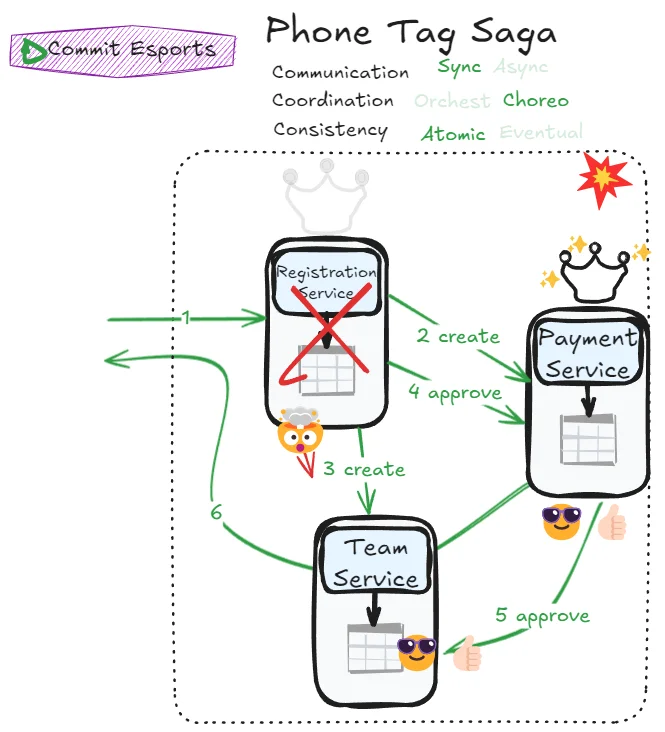
Handling mediator crash
So what is the clear win here?
The answer: fault tolerance. If the coordinating service fails, other services can elect a new coordinator to complete the transaction using consensus algorithms (like Raft or Paxos). You pay for additional complexity but gain resilience against coordinator failure.
Pros:
- Strong consistency guarantees
- Better fault tolerance than centralized orchestration
Cons:
- Hidden complexity: Usually requires a “hidden” coordinator role, creating coupling despite the choreography appearance. Or worse, you just assume every participant has to know about each other’s vote to complete the transaction.
- Distributed coordination burden: All services share responsibility for ensuring global atomicity, significantly increasing implementation complexity
This pattern is rarely implemented outside of specialized distributed databases and coordination systems. The complexity typically isn’t justified for business applications.
Horror Story Saga
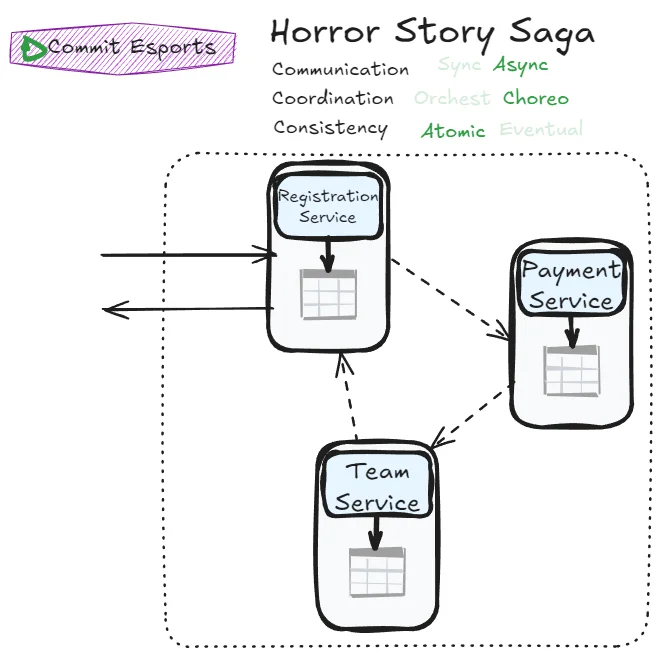
Achieving atomicity with asynchronous communication is difficult (Fantasy Fiction Saga). Achieving it without an orchestrator is also difficult (Phone Tag Saga). But what if we combine both challenges?
Meet the Horror Story Saga:
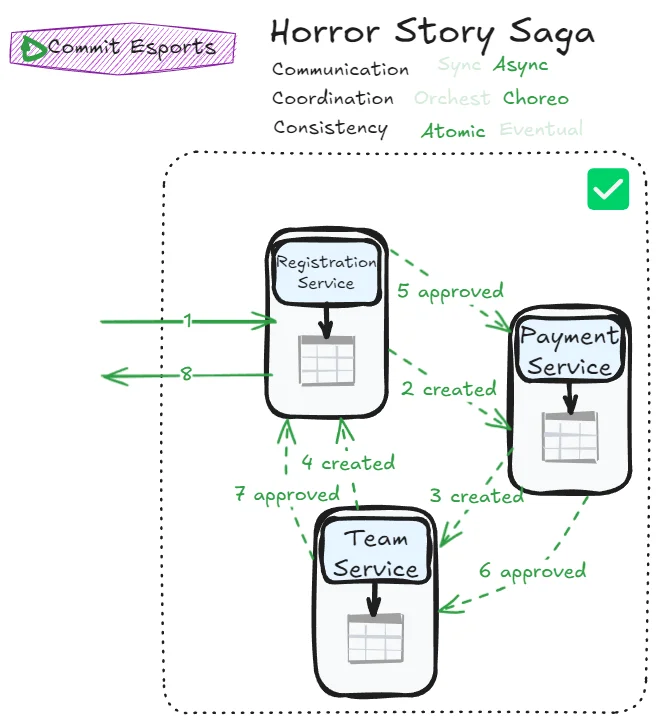
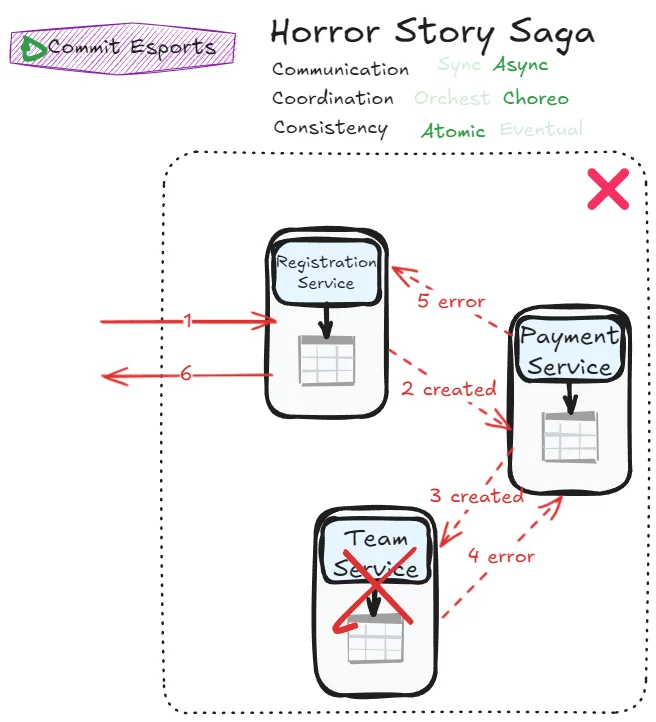
The CAP theorem tells us: in distributed systems facing network partitions, choose between Consistency and Availability. You can’t have both. The Horror Story Saga tries to have both anyway.
The result? A system with countless failure scenarios and nearly impossible error management. Even the success case is extraordinarily difficult to implement. You’re asking all participants to communicate through messaging, knowing as little as possible about each other, while somehow achieving atomicity without a coordinator.
In practice, this often results in tightly coupled code disguised as choreography—you’re just hiding the complexity, not eliminating it. You cannot avoid the necessary coordination entropy; fighting against it makes things worse. (See my entropy article if this topic interests you.)
Pros:
- Strong consistency guarantees (in theory)
Cons:
- Extraordinarily difficult to implement:
- All services must track global transaction state
- But asynchronous nature tries to decouple that tracking
- Multiple transactions can be managed concurrently, potentially out of order
- The multiplicity and complexity of error conditions are overwhelming
- Can yield terrible responsiveness: Despite async communication, atomic requirements create bottlenecks.
Don’t implement this pattern. If you think you need it, reconsider your architecture.
Time Travel Saga
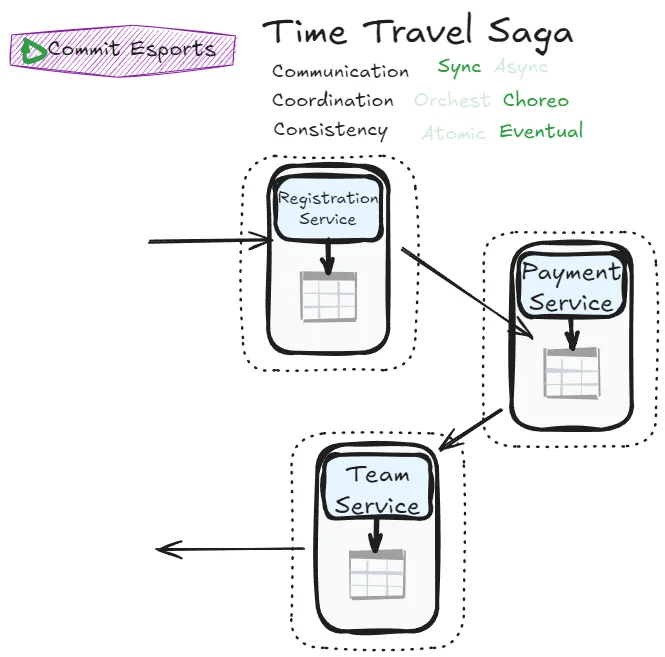
What happens when we take the Phone Tag Saga but relax the atomicity constraint?
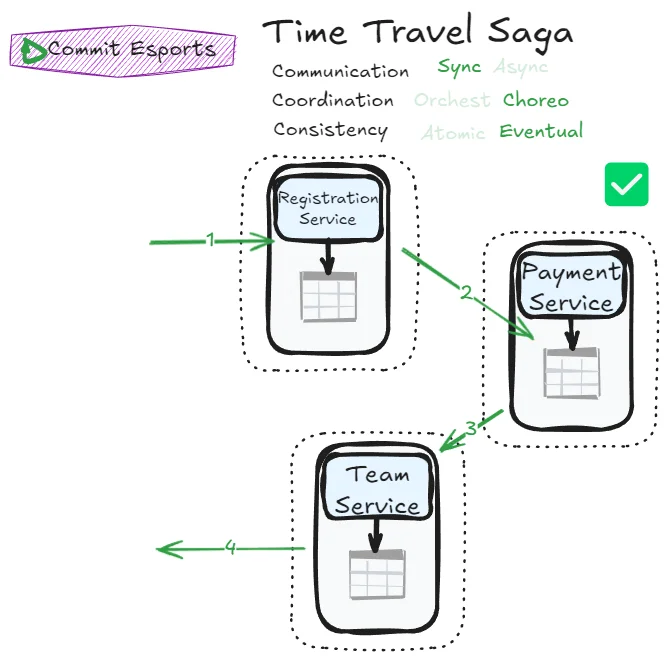
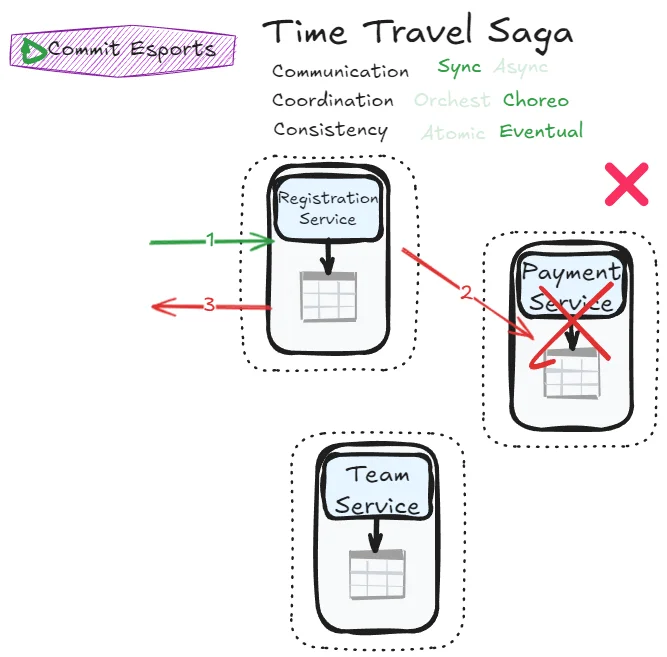
This is the simplest choreography pattern to reason about. Error management becomes easier because the previous service in the chain can immediately handle failures. Each service doesn’t need deep knowledge of other services thanks to eventual consistency.
We’re building a genuinely high-availability system. But can we make it even more available, loosely coupled, and fault-tolerant?
Yes. Meet the Anthology Saga.
Anthology Saga
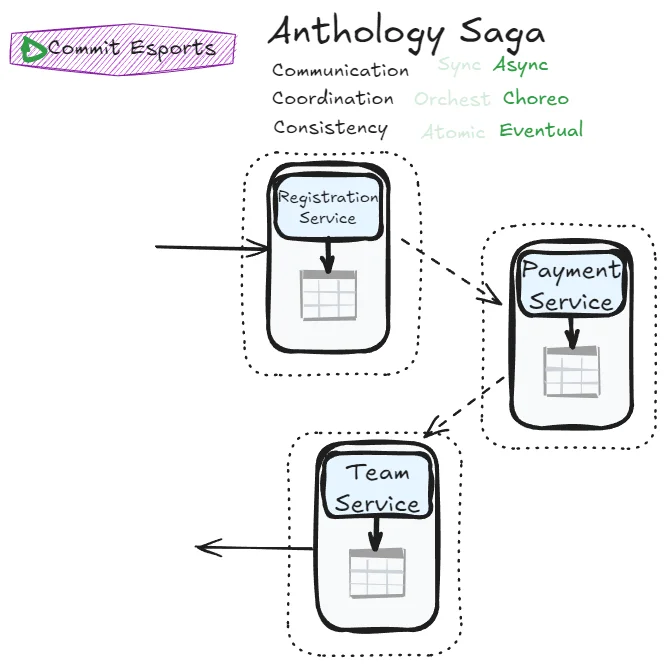
The most decoupled architecture possible:
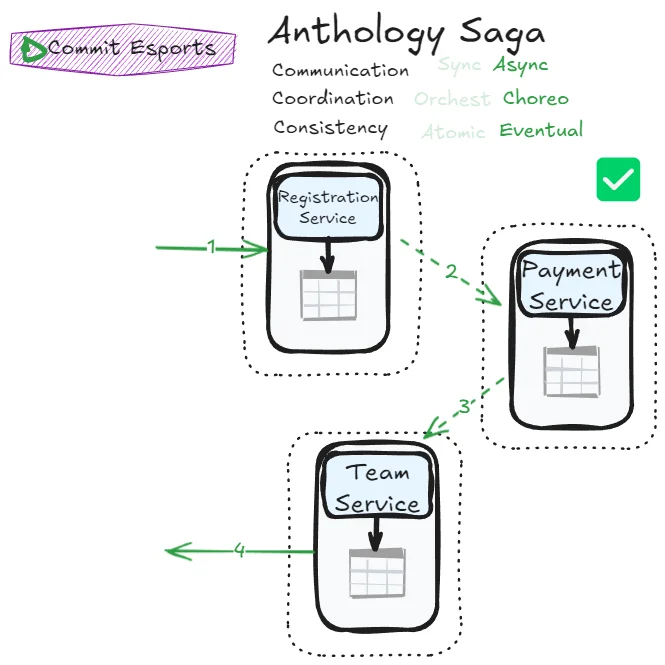
This pattern achieves true independence between services. Each service publishes events describing what happened. Other services subscribe to relevant events and react accordingly. No service needs to know who’s listening or what they’ll do with the information.
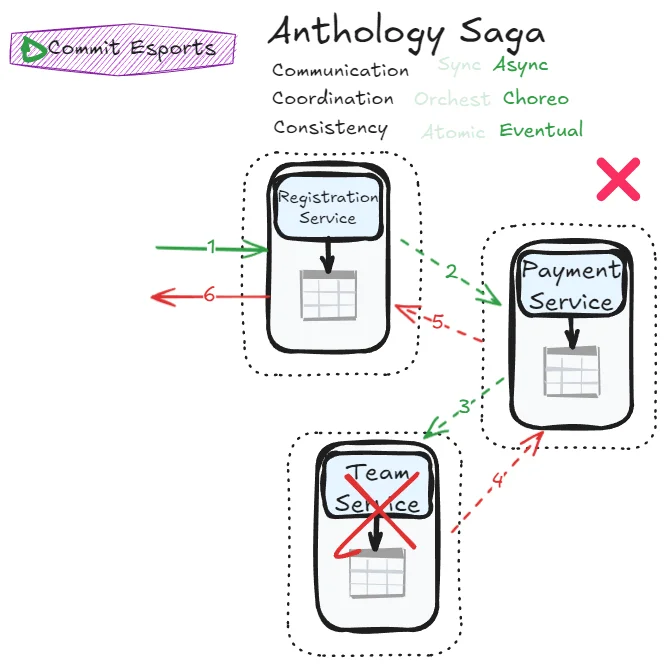
The cost? Error management flows become more complex. You need comprehensive monitoring and observability to understand what’s happening across the system.
This is the modern ideal for large-scale, high-agility systems. It scales best when you need multiple teams working independently, handling heavy user loads, and evolving rapidly.
Pros:
- Highly decoupled:
- Asynchronous messaging decouples producers from consumers
- Transactions scoped at the service level
- No central mediators
- Highly responsive:
- No bottlenecks from central coordinators
- Eventual consistency and async nature enable fire-and-forget message patterns
- Highly scalable: Same properties that enable responsiveness also enable horizontal scaling
Cons:
- Error handling complexity: Without a central orchestrator, understanding and fixing failures requires sophisticated monitoring
- Eventual consistency: Users may see temporary inconsistencies
This is the pattern that companies like Netflix, Amazon, and Uber use at scale. It requires mature engineering practices but delivers exceptional scalability and agility.
Saga Patterns Summary
All 8 Saga Patterns at a Glance
| Saga Pattern | Communication | Coordination | Consistency | Comment |
|---|---|---|---|---|
| 🟢 Fairy Tale Saga | Synchronous | Orchestration | Eventual | Simple, practical pattern for most use cases requiring coordination |
| 🟢 Parallel Saga | Asynchronous | Orchestration | Eventual | Good responsiveness with central coordination; ideal for decoupling and good error management |
| 🟢 Anthology Saga | Asynchronous | Choreography | Eventual | Maximum scalability and decoupling; the modern ideal for high-agility systems |
| 🟡 Epic Saga | Synchronous | Orchestration | Atomic | Strong consistency but high coupling; essentially XA at application level |
| 🟡 Time Travel Saga | Synchronous | Choreography | Eventual | Simplest choreography pattern; easier error management than other choreography patterns |
| 🔴 Fantasy Fiction Saga | Asynchronous | Orchestration | Atomic | Too complex for the benefits; avoid in most cases |
| 🔴 Phone Tag Saga | Synchronous | Choreography | Atomic | Complexity without clear wins; avoid in most cases |
| 🔴 Horror Story Saga | Asynchronous | Choreography | Atomic | Nearly impossible to implement correctly; don't use |
🟢 Recommended for production • 🟡 Use with caution • 🔴 Avoid in most cases
Choosing your saga pattern
The Commit Esports team stares at the whiteboard, now covered with eight different patterns.
“So which one should we use?” asks a developer.
The architect smiles. “That’s the wrong question. The right question is: which ones should we use, and where?”
Different parts of your system have different requirements:
Saga Pattern Selection Guide
Wrap up
We’ve journeyed from monolithic databases to microservices data ownership. We’ve explored access patterns that balance consistency with autonomy. And we’ve discovered eight saga patterns that coordinate transactions across service boundaries.
The Commit Esports team now has the tools they need. They understand that:
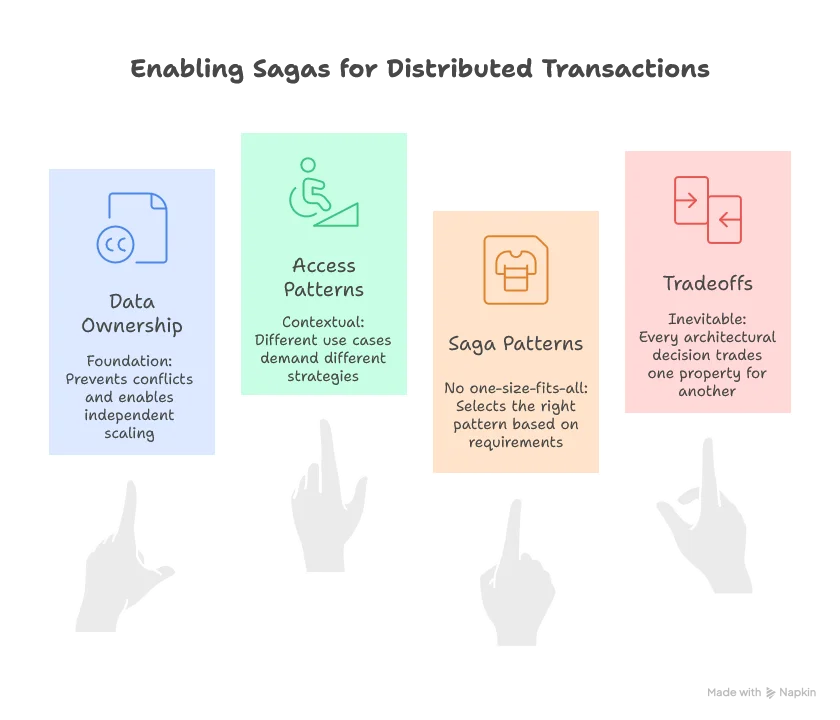
Most importantly, they’ve learned that distributed systems aren’t about finding the “perfect” solution. They’re about making informed tradeoffs that align with your business needs, your team’s capabilities, and your system’s constraints.
The hard parts of software architecture? They’re hard because they force you to make difficult choices. But armed with these patterns and principles, you’re equipped to make those choices wisely.
Your distributed system won’t be perfect. But with careful thought and deliberate design, it will be good enough—and that’s what matters.