
ACID and Saga Fundamentals
Prelude
This article is heavily based on two fantastic books:
- Software Architecture, the hard parts, by Neal Ford, Mark Richards, Pramod Sadalage and Zhamak Dehghani
- Designing Data-Intensive Applications, by Martin Kleppmann
Both books tackle distributed transactions brilliantly—the former through an engineering lens, the latter from a more academic perspective. What makes this article unique is how we’ll bridge these two worlds, building rock-solid fundamentals that you can actually apply to real systems.
Recap: The data ownership foundation
In the previous article, we helped Commit Esports—a fictive esports platform—survive their scaling crisis by migrating from a monolith to microservices. We tackled the hardest part of that migration: breaking apart their database.
We established clear data ownership patterns (single, common, and joint ownership) and explored five data access strategies for reading across service boundaries—from synchronous interservice communication to data replication, caching patterns, and shared data domains. Each pattern made different tradeoffs between consistency and autonomy.
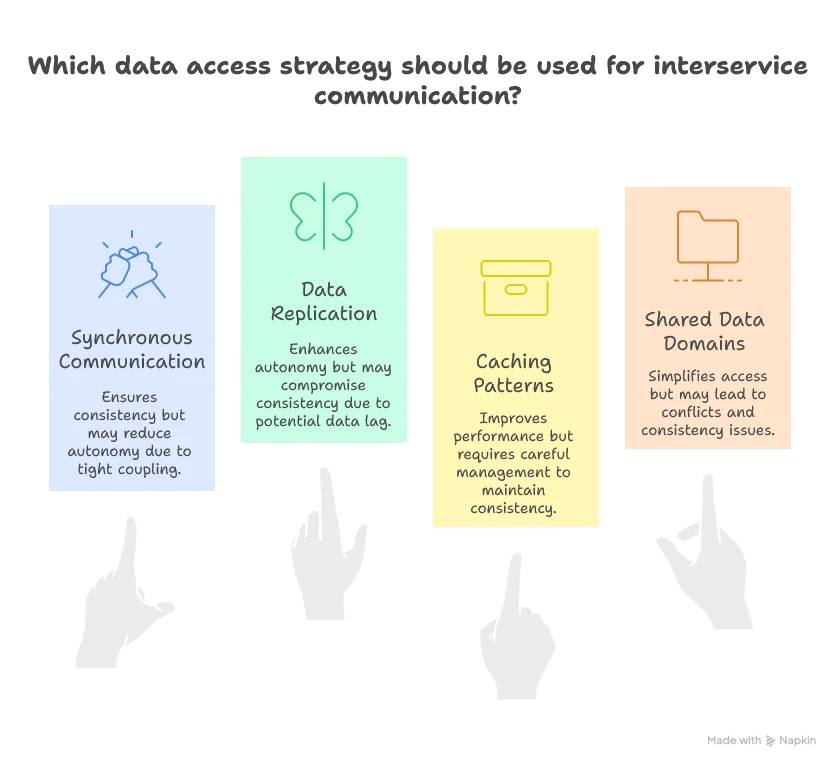
But we left one critical question unanswered: What happens when a single business operation needs to write to multiple services? In their monolith, Commit Esports relied on database transactions to guarantee atomicity. Charge the entry fee, create the registration, update tournament capacity—all or nothing. Now those operations live in separate services with separate databases. No shared transaction coordinator. No ACID safety net.
That’s the problem we’re solving today: maintaining consistency across service boundaries when operations span multiple data owners. Welcome to the world of distributed transactions and sagas.
Understanding the nuance of ACID
[This section draws heavily from Martin Kleppmann’s perspective on ACID transactions in “Designing Data-Intensive Applications.”]
You’ve heard of ACID transactions. But do you truly understand the nuances? Let’s find out.
ACID stands for Atomicity, Consistency, Isolation, and Durability. Here’s the challenge: Can you explain the concrete differences between what Atomicity, Consistency, and Isolation guarantee? Aren’t they all just different flavors of consistency?
Let’s play a game. I’ll present what I believe most people understand about each property, and you try to guess whether the definition is accurate.
Atomicity
Consistency
Isolation
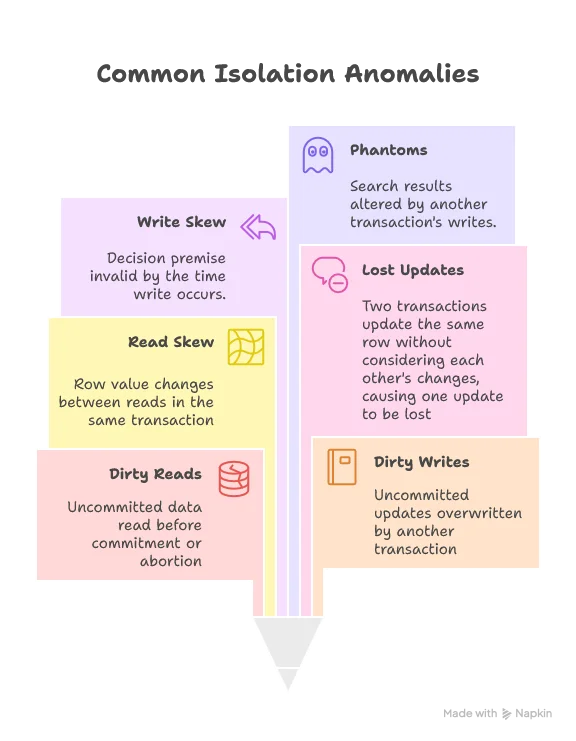
Durability
Sagas
This section draws heavily from Mark Richards and Neal Ford’s book, while incorporating Martin Kleppmann’s rigorous treatment of atomicity.
The Commit Esports team sits around the conference table, exhausted. They’ve successfully broken apart their monolith. They’ve established clear data ownership. They’ve chosen appropriate access patterns for each use case. Everything should be working smoothly now.
But there’s a problem.
“The tournament registration is broken,” the lead developer announces, pulling up logs on the screen. “A team paid their entry fee—payment service committed the transaction successfully. But then the tournament service timed out when trying to update the capacity. Now we’ve charged them, but they’re not registered. And we can’t just roll back the payment because that transaction already committed to its database.”
The room falls silent. This is the harsh reality of distributed systems: you can’t wrap multiple services in a single ACID transaction. Each service has its own database, its own transaction boundary. When operations span services, you lose the safety net that monolithic databases provided.
Welcome to the world of sagas—the patterns that let you maintain consistency across service boundaries when traditional ACID transactions can’t help you.
Defining sagas: Then and now
The original saga definition, introduced in 1987, was straightforward: “A saga is a sequence of local transactions. Each local transaction updates the database and publishes a message or event to trigger the next local transaction in the saga. If a local transaction fails because it violates a business rule, then the saga executes a series of compensating transactions that undo the changes that were made by the preceding local transactions.”
This definition served the distributed systems community well for decades. But today’s microservices architectures demand a broader understanding. A more modern definition recognizes the full spectrum:
A saga manages long-running, distributed transactions by breaking them into a sequence of local transactions.
Let’s unpack what this really means:
To truly understand modern sagas, we need to explore the three dimensions that define their implementation.
The three dimensions
Saga implementations vary across three fundamental dimensions:
- Communication: Synchronous vs. Asynchronous
- Coordination: Orchestration vs. Choreography
- Consistency: Atomic vs. Eventual Consistency
Let’s examine each dimension in detail.
Communication: The protocol layer
In our earlier discussion of data access strategies, we focused on what data to exchange and when. Now we need to address how—the protocols and communication patterns that make sagas work.
REST
REST is an architectural style, and services implementing it are called RESTful services. Most developers recognize REST as a set of HTTP endpoints with standard “verbs” (GET, POST, PUT, DELETE, PATCH).
A purist’s note: Many so-called “RESTful” services are actually RPC in disguise. True REST includes stricter constraints like hypermedia controls following the Hypermedia as the Engine of Application State (HATEOAS) principle. But in practice, most teams use a pragmatic subset: JSON payloads with conventional URL patterns.
REST communications are typically synchronous—the client makes a request and waits for a response:
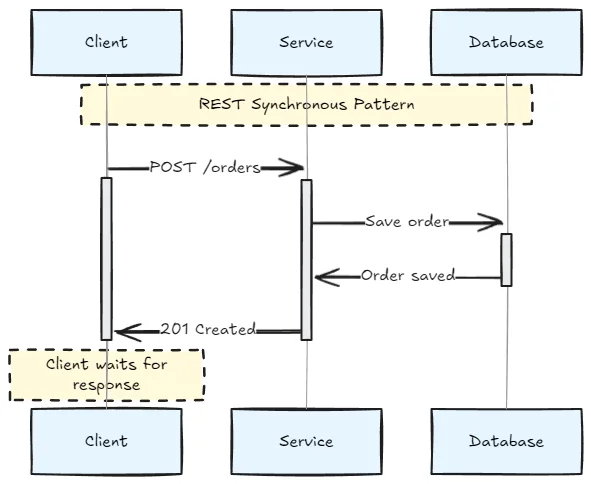
However, you can simulate asynchronous behavior with callbacks or polling:
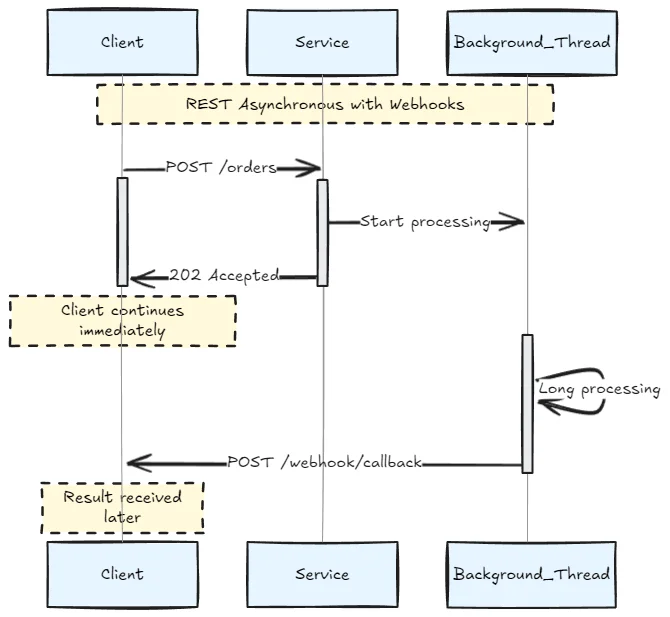

North-south communication (external clients to services).
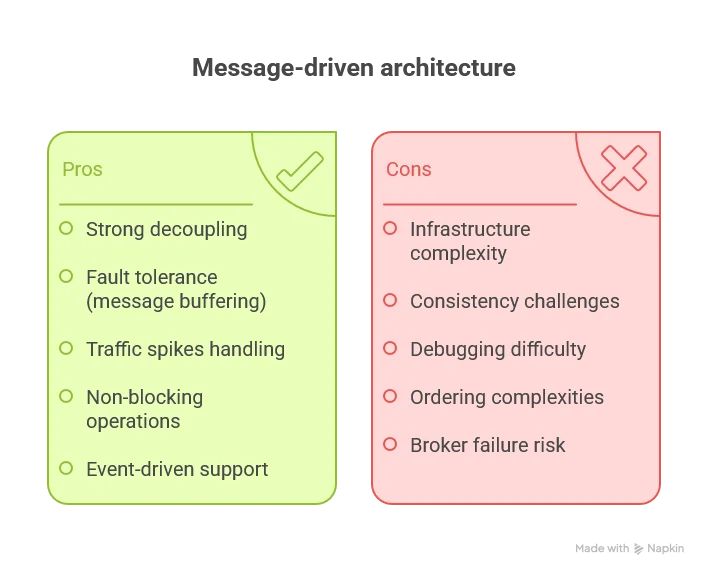
Messaging
Messaging relies on intermediary message brokers (RabbitMQ, Kafka, ActiveMQ, AWS SQS, Azure Service Bus) where producers send messages to queues or topics, and consumers retrieve them asynchronously.
Messaging is inherently asynchronous:
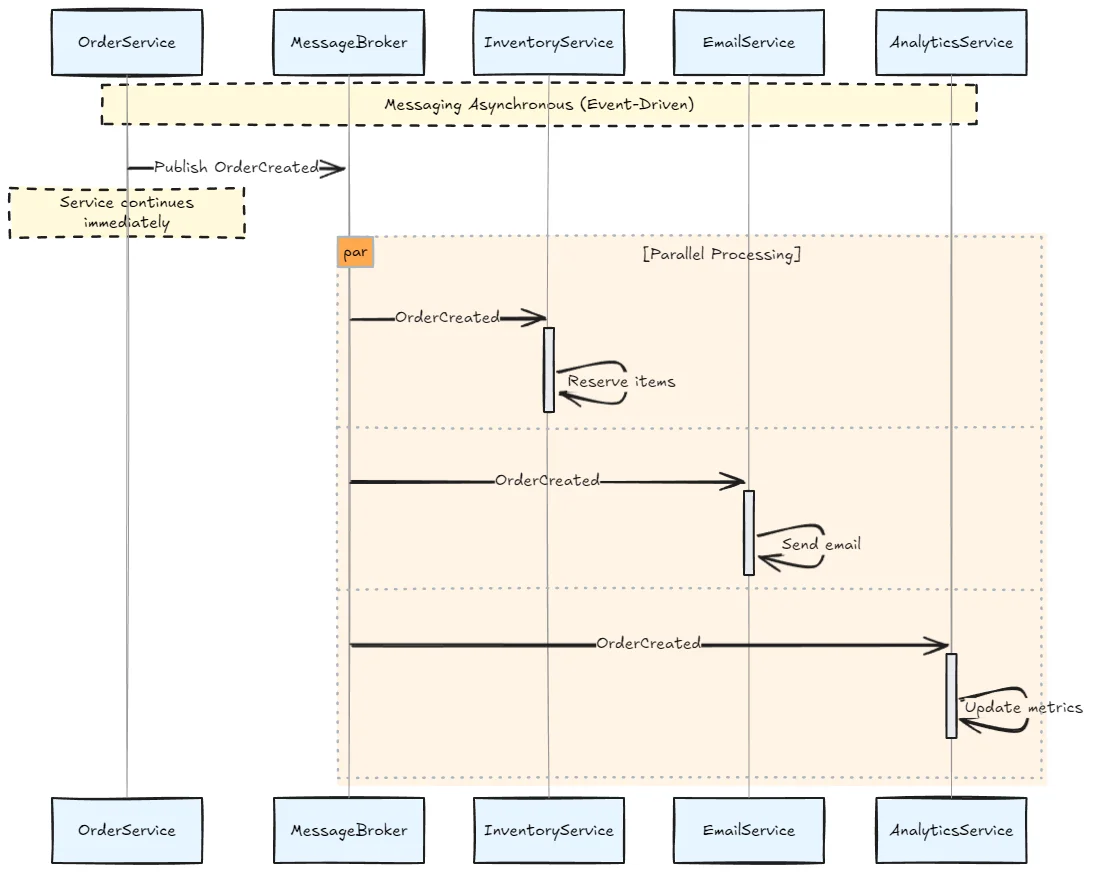
Though you can simulate synchronous patterns with request-reply queues:
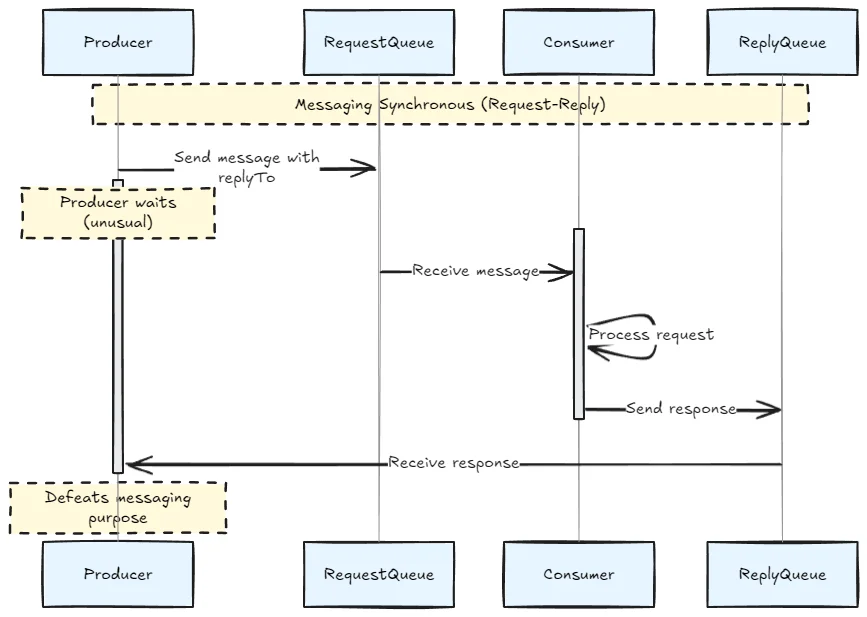
East-west communication (service-to-service) when decoupling and asynchronous processing are priorities.
gRPC
Google Remote Procedure Call (gRPC) is a framework using Protocol Buffers for serialization and HTTP/2 for transport. It supports both synchronous and asynchronous communication patterns.
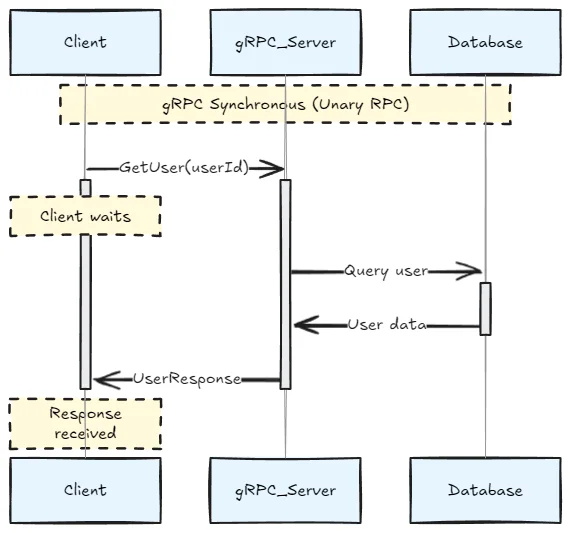
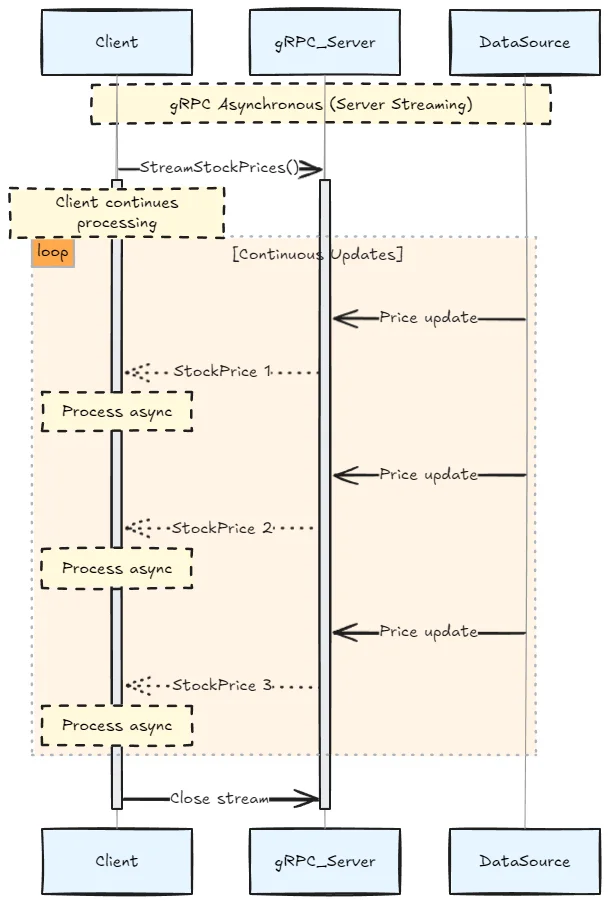
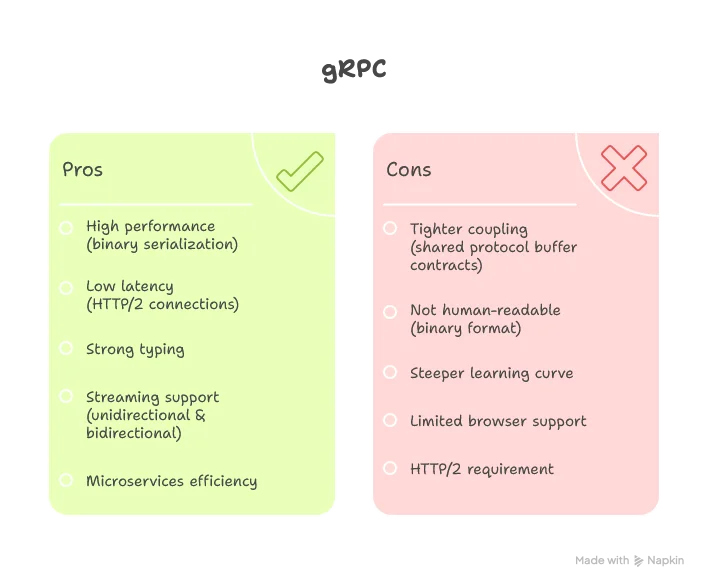
East-west communication (service-to-service) with low-latency requirements.
Coordination: Who’s in charge?
The Commit Esports team faces a crucial decision: should they use orchestration or choreography for their tournament registration process? The workflow spans multiple services—registration, team validation, payment, and email notifications. Someone (or something) needs to coordinate this dance.
Orchestration: The conductor pattern
In orchestration, a central orchestrator service manages the entire transaction lifecycle. Think of it as a conductor directing an orchestra—it knows the score, cues each musician, and handles any mistakes.
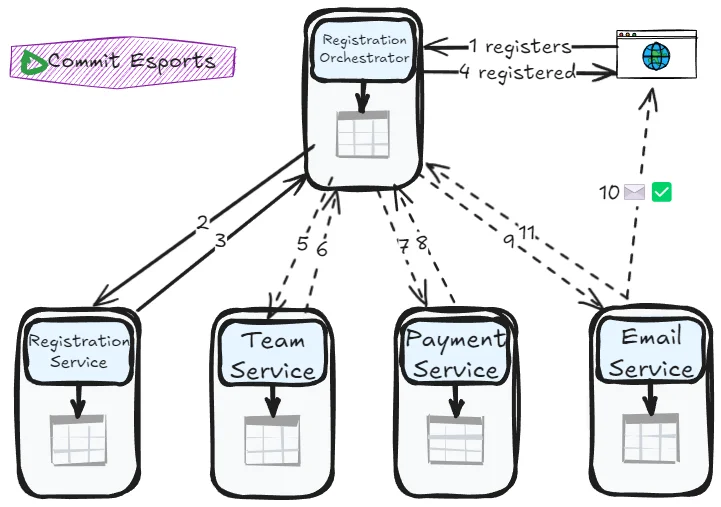
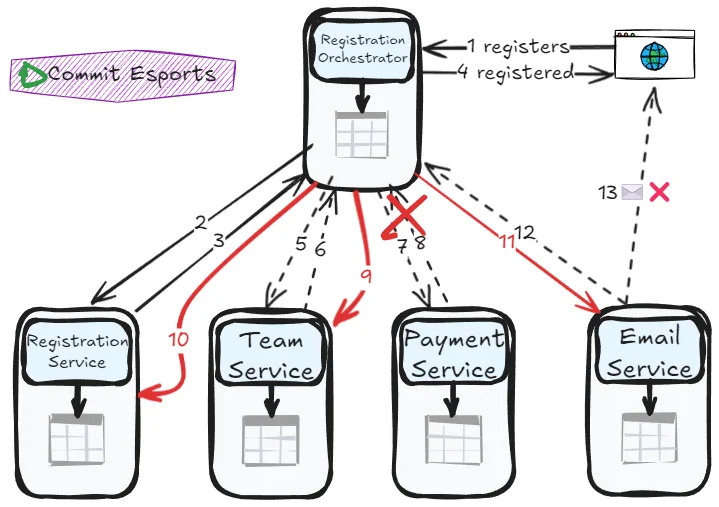
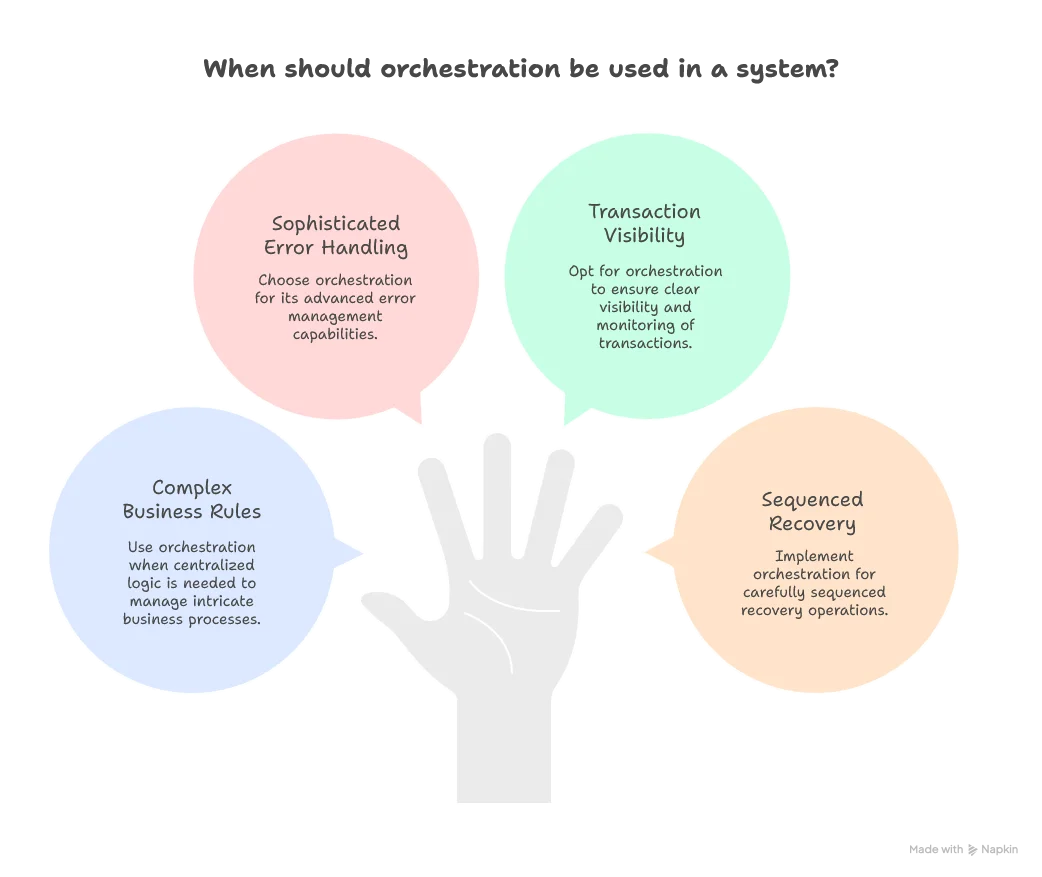
Tradeoffs:
- Pros: Clear transaction flow, easier debugging, centralized error handling
- Cons: Orchestrator becomes a single point of failure, potential bottleneck, tighter coupling to orchestrator service
Choreography: The dance pattern
In choreography, no central coordinator exists—each service knows its role and responds to events from other services. Like dancers in a choreographed performance, each service knows when to act based on what others do.
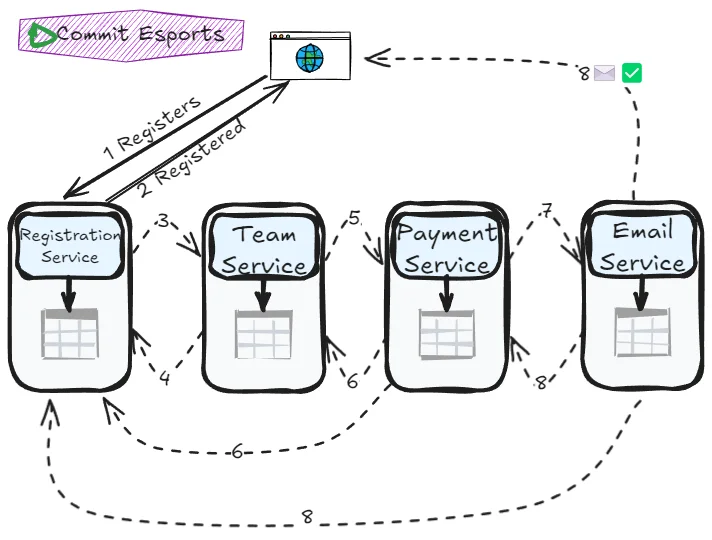
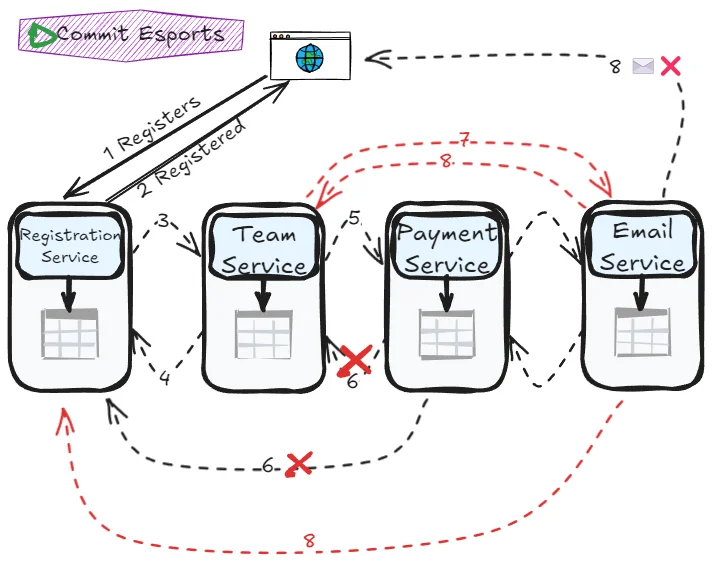
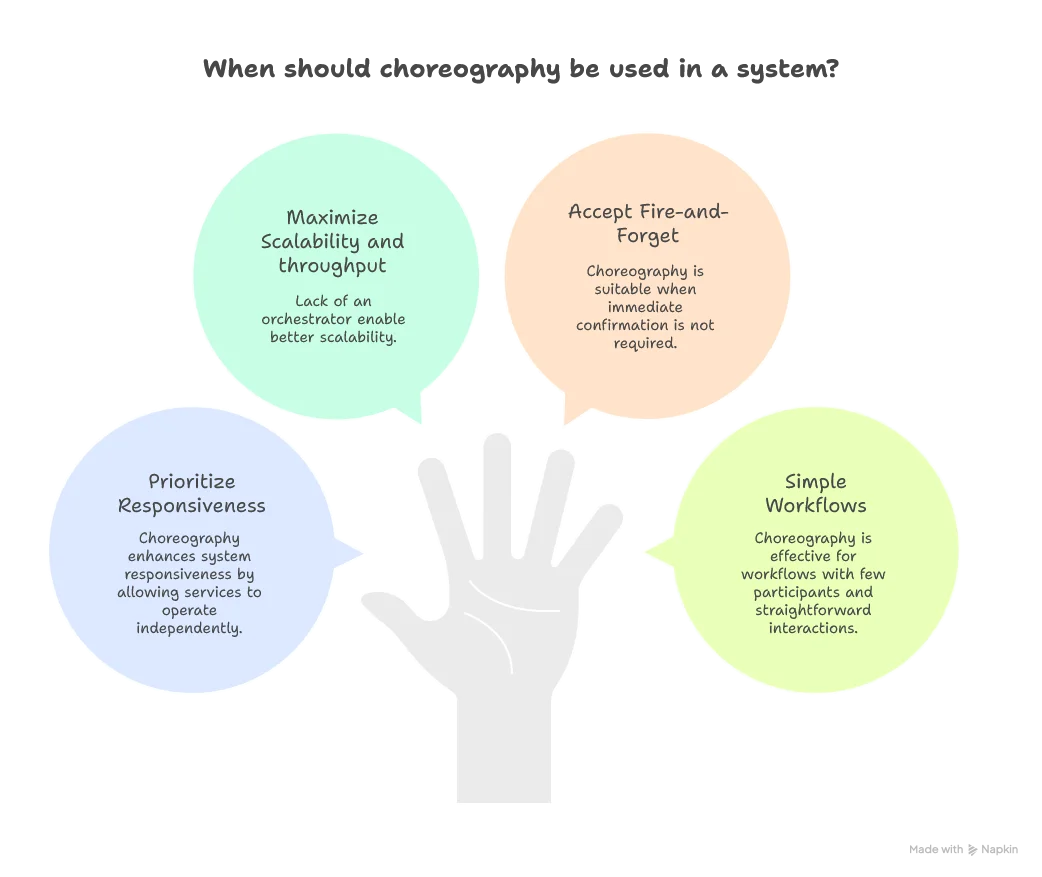
Tradeoffs:
- Pros: No single point of failure, better scalability, lower latency
- Cons: Harder to understand complete flow, debugging complexity, risk of cyclic dependencies
Orchestration vs Choreography
Consistency: The spectrum of guarantees
Here’s where we need to be careful with terminology. Consistency isn’t a binary choice between “atomic” and “eventual.” And what do we really mean by “consistency”? Perfect isolation? ACID-style atomicity? Something else entirely?
For our discussion, let’s establish clear definitions:
- Atomic consistency: The saga provides ACID-style atomicity—either all services agree to commit the transaction, or all services agree to abort it
- Eventual consistency: The saga coordinates operations but doesn’t guarantee atomicity; the system may temporarily show impossible statements during execution
The choice between these depends on your business requirements and the tradeoffs you’re willing to make.
XA transactions: The controversial option
Introduced in 1991, X/Open XA (eXtended Architecture) is a standard for implementing two-phase commit (2PC) across heterogeneous technologies. It’s supported by many databases (PostgreSQL, MySQL, DB2, SQL Server, Oracle) and message brokers (ActiveMQ, HornetQ, MSMQ, IBM MQ).
Two-phase locking is an algorithm to achieve a serializabality isolation, while two-phase commit is to achieve atomicity.
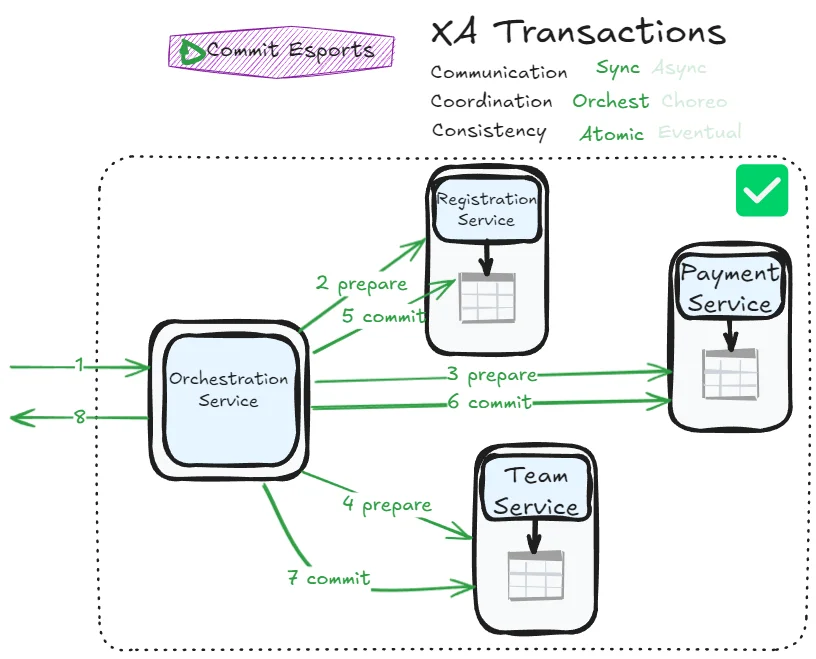
Two-phase commit works in two phases:
- Prepare phase (voting): The coordinator gives instructions and asks each participant, “Can you commit?”
- Commit/Abort phase (decision): Based on the votes, the coordinator tells everyone to either commit or abort
The main purpose of this protocol is to ensure atomicity—in the ACID sense—over a distributed transaction.
How it works:
XA is essentially an API for interfacing with a transaction coordinator. In Java ecosystems, XA transactions are implemented using the Java Transaction API (JTA), with support through JDBC drivers for databases and JMS APIs for message brokers.
XA assumes your application uses network drivers to communicate with participant databases or messaging services. The driver exposes callbacks through which the coordinator can ask participants to prepare, commit, or abort.
In practice, the coordinator is a library loaded into the same process as the application issuing the transaction. It maintains a log on local disk to track the commit/abort decision for each transaction.
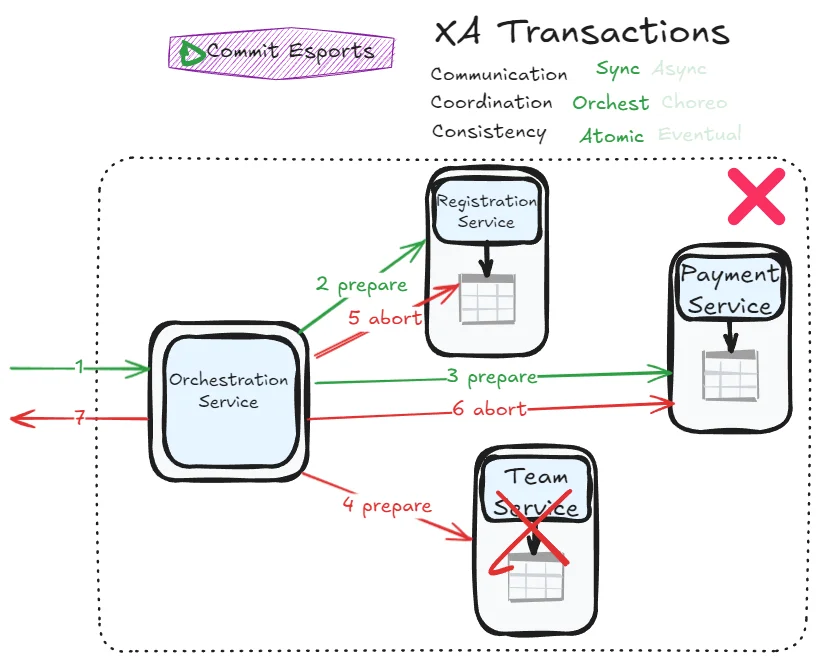
The problems:
If the application crashes, the coordinator goes with it. Any participants with prepared but uncommitted transactions are stuck “in doubt”. This can lead to row-level exclusive locks held indefinitely, blocking other transactions from accessing those rows.
In theory, restarting the coordinator reads the log and resolves all in-doubt transactions. In practice, orphaned in-doubt transactions do occur, and manual administrator intervention becomes necessary. Rebooting database servers won’t fix this—if 2PC is correctly implemented, the database will maintain the in-doubt state until the coordinator decides.
A concrete example for Commit Esports:
The verdict:
Remember the First Law of Software Architecture: everything in software architecture is a tradeoff. While XA transactions have earned a terrible reputation in the microservices world, they may still be appropriate for specific scenarios where strong consistency outweighs availability concerns.
However, their bad reputation is well-deserved. By choosing XA transactions, you’re essentially importing one of the monolith’s most significant flaws—blocking, coordinated commits—into your distributed system. You’ve distributed your system’s components but retained its most problematic coupling mechanism.
For most modern microservices architectures, sagas provide a more pragmatic path forward.
Mark Richards and Neal Ford’s saga taxonomy
If we treat each dimension as a binary choice, we can theoretically implement 2 × 2 × 2 = 8 different types of sagas. While some combinations prove impractical in real-world systems, this taxonomy serves as a powerful mental model. It helps us understand why certain patterns emerge naturally while others feel forced.
But exploring these eight patterns requires more than a quick overview. Each pattern has its own character, its own tradeoffs, its own place in the architectural toolbox. Some are elegant and practical. Others are complex warnings about paths best avoided.
In the next article, we’ll systematically explore all eight saga patterns—from the straightforward Epic Saga to the wonderfully decoupled Anthology Saga, and yes, even the aptly named Horror Story Saga. We’ll see concrete examples of how Commit Esports might apply each pattern, understand when to choose one over another, and learn which patterns to avoid entirely.
The journey from theory to practice continues. Let’s meet these eight patterns and discover which ones belong in your architectural repertoire.