
Data Ownership
Prelude
This article is heavily based on two fantastic books:
- Software Architecture, the hard parts, by Neal Ford, Mark Richards, Pramod Sadalage and Zhamak Dehghani
- Fundamentals of Software Architecture, by Mark Richards, Neal Ford
Fundamentals of Software Architecture explains the key architecture characteristics as well as a detailed overview of monolith and microservices architectures.
Software Architecture, the hard parts tackles breaking monoliths into microservices brilliantly. This article aims to summarize the specific issues arising from breaking the hardest layer: the data layer.
What’s in it for you
Breaking Monoliths into Microservices is hard.
Meet Commit Esports, our fictive company that’s about to learn this lesson the hard way. They built a monolithic application that worked beautifully. Business was booming. Life was good.
Then came the irony: they became too successful.
Their system started buckling under its own weight. Complexity spiraled out of control. User traffic exploded. And now? They’re staring down the barrel of a complete system collapse—victims of their own success.
Let’s help them survive.
Understanding their architectural needs
Commit Esports started simple: a straightforward system for esports teams to register for tournaments with a modest fee. Clean. Focused. Effective.
Then success happened.
They added pool management. The platform took off. Statistics for players? Sure, why not—they could even auto-elect MVPs now. Then came anti-cheat features to ensure fair play. Each new feature brought more players, more use cases, more complexity.
The cracks started showing. Implementing one feature would mysteriously break three others. When they opened registration for the next big tournament, the system simply… crashed. Too many users. Too many matches to schedule. Too many concurrent operations. The database groaned under the load—rows locked, transactions queued, more locks acquired, more transactions waiting. A vicious cycle.
They tried horizontal scaling. Consistency problems emerged, and operational costs skyrocketed. Vertical scaling restored consistency temporarily, but it was even more expensive. And eventually? They hit the ceiling. You can only buy so much hardware.
Was this the end for Commit Esports?
That’s what they thought—until they realized the real problem wasn’t their code. It was their architecture. The monolith had served them well, gotten them this far. But now it was time to evolve or die.
Why monoliths don’t scale well
Let me be clear: monolithic architectures aren’t bad. In fact, Mark Richards and Neal Ford established the First Law of Software Architecture: everything in software architecture is a tradeoff.
Monoliths excel in many ways: low operational complexity, no versioning headaches, reliable strong consistency, and straightforward debugging. For modest, constant workloads with highly interdependent components, you might even see better performance, security, and cost management.
The problem? Monoliths hit walls. Multiple walls. All at once.
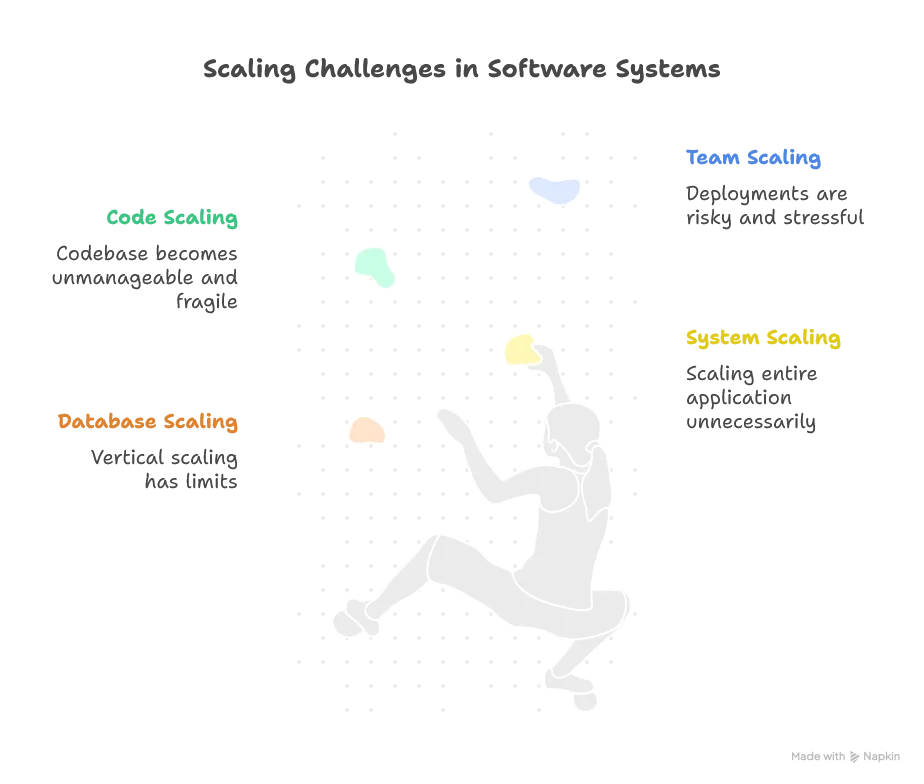
Database scaling: You’re stuck with a single database, forcing expensive vertical scaling. And vertical scaling has hard limits—physics eventually says “no.”
System scaling: Sure, you can scale horizontally, but now you’re scaling your entire application just because one part needs it. You’re paying to scale components that don’t need scaling at all.
Code scaling: Your codebase grows into a “big ball of mud.” Change one thing, break five others. Testing becomes a nightmare—true unit tests become nearly impossible, and suddenly a single change breaks dozens, maybe hundreds, of tests. Code ownership gets murky. Governance becomes a political nightmare.
Team scaling: Deploying means blocking an entire weekend. Developers, testers, business owners, architects—everyone’s on high alert. The bigger the system, the higher the stakes, the more sweaty palms.
The result? Agility plummets. Database performance degrades. The whole system becomes a liability.
Here’s the ironic part: starting with a monolith is actually common. Smart, even. There’s a fascinating parallel between system architecture and organizational structure. Companies start small, and monoliths thrive in that environment. But as you scale—more use cases, more users—you need bigger teams. Your organization grows. Your architecture must grow with it.
Pro tip: Even if you’re building a monolith, architect it as a modular monolith (or “modulith”). One deployment doesn’t mean one giant mess. Organize your code into independent, business-oriented components that can be extracted and deployed individually later. Future-you will be grateful.
This is exactly where Commit Esports landed. Time to introduce them to microservices.
Enter microservices
Microservices decouple your system into independently deployable services, each doing one specific thing well. Despite the name, “micro” doesn’t mean tiny—it refers to their number. Each service becomes independent, with its own lifecycle, enabling steadier, more predictable delivery.
The tradeoff? Higher operational complexity and greater team maturity requirements. Fortunately, automation can mitigate both. What’s harder to mitigate however is versioning complexity, network latency and keeping your distributed transactions ACID-compliant.
For this article, let’s assume Commit Esports has already split their logical services. One problem remains: the data domain.
Mark Richards and Neal Ford present several strategies for this. Let’s dive in.
Data ownership
Commit Esports successfully split their monolith into independent services. Great! But they’re still stuck with one massive database. And that’s the bottleneck preventing a true microservices architecture:
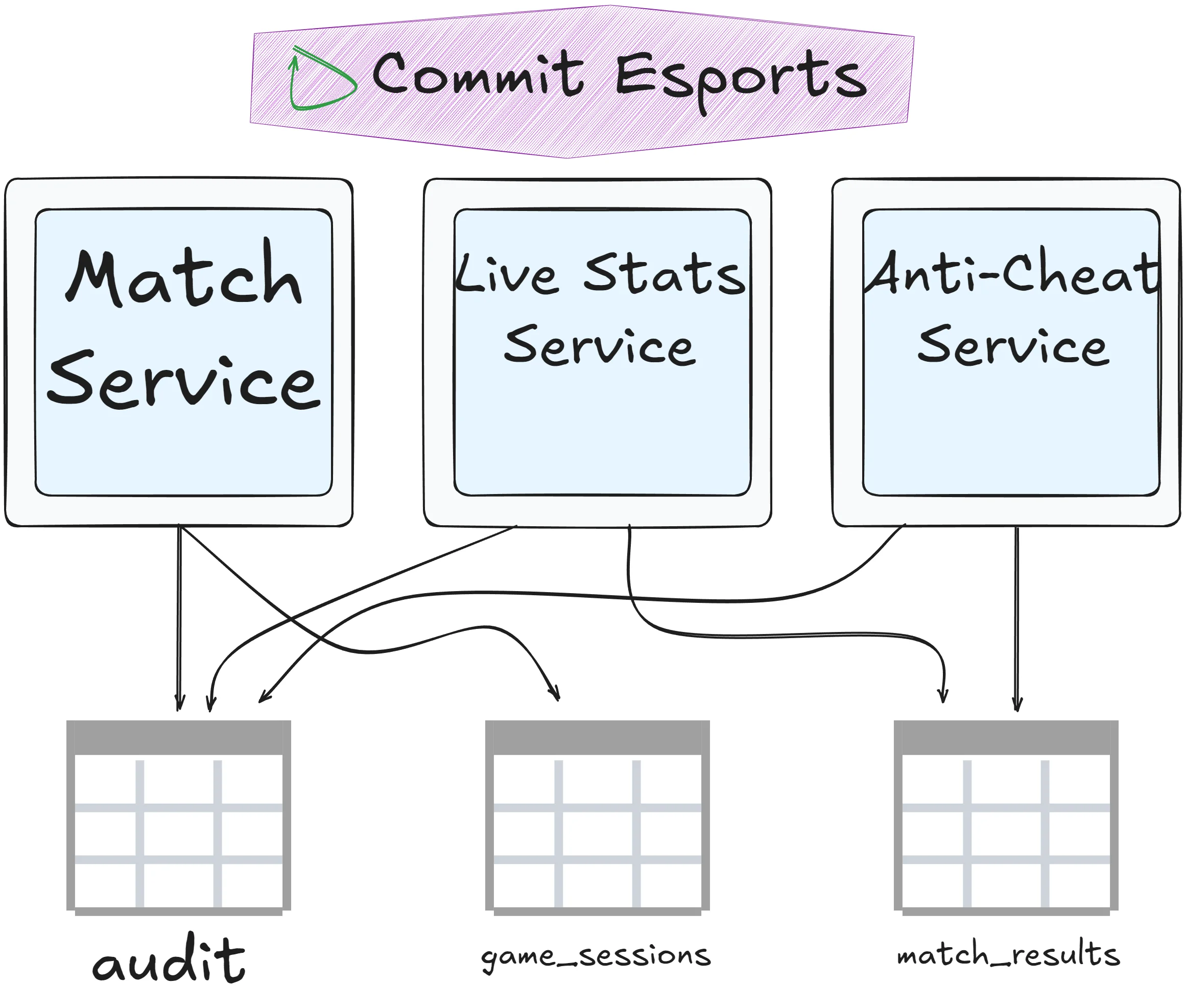
The golden rule: The owner of a table is the one who writes to it.
Data Ownership Decision Framework
Single ownership
This is the dream scenario. Just move the table into the service’s bounded context:
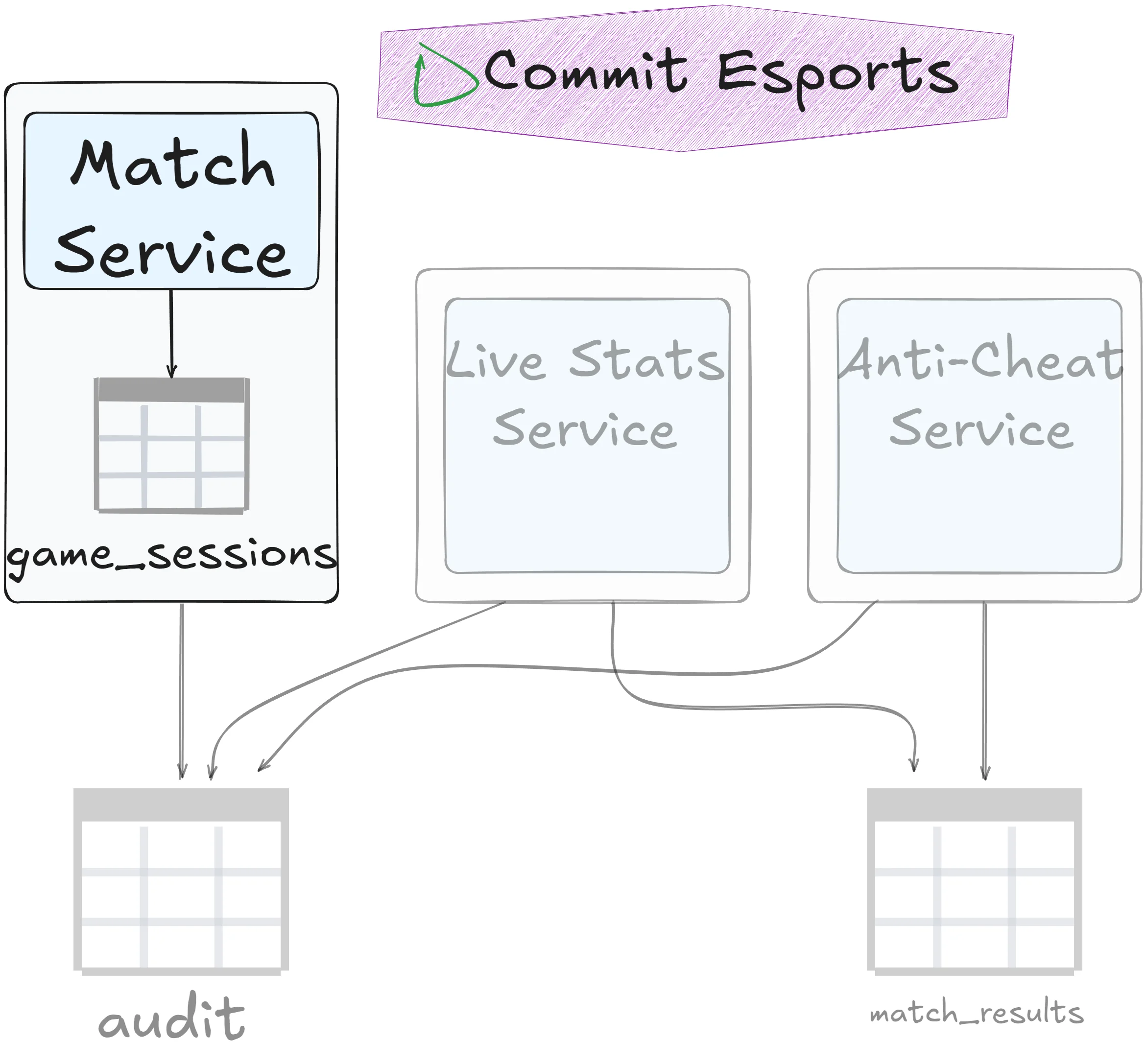
Easy. Clean. Done.
Common ownership
Create a dedicated service to manage writes. Other services send messages requesting write operations:
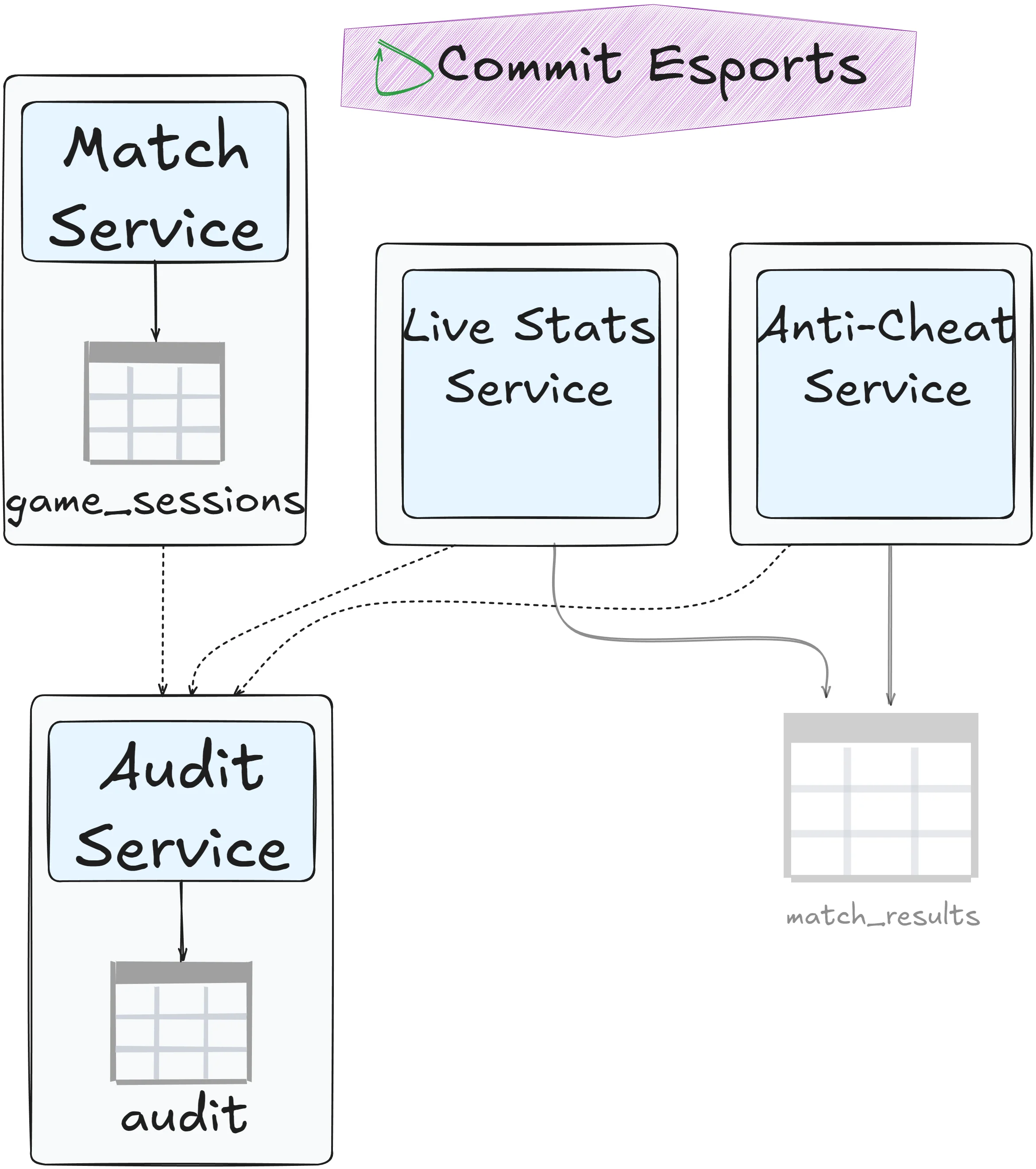
This centralizes control while maintaining clear ownership.
Joint ownership
Now things get interesting. You have four strategies:
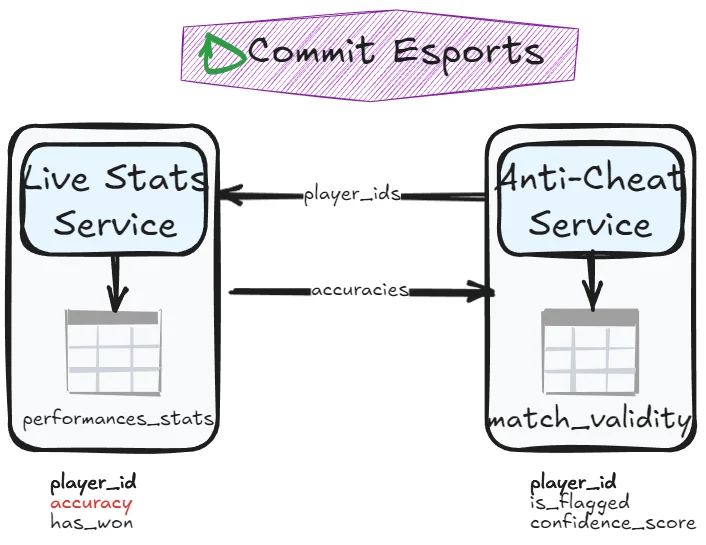
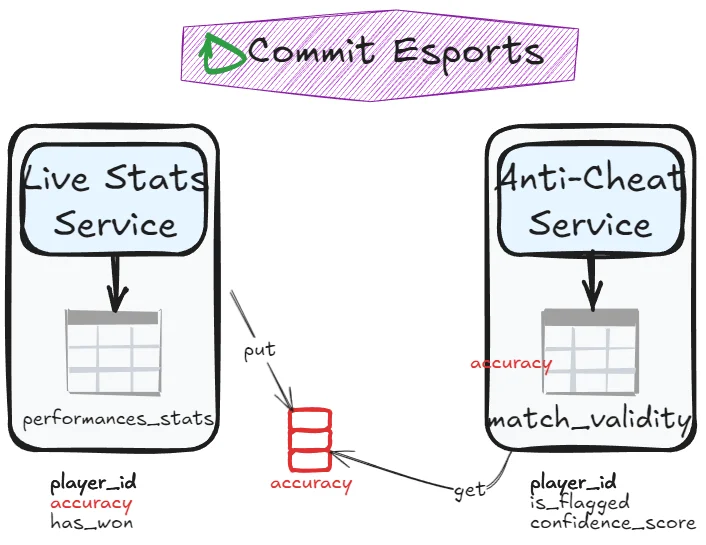
Table split
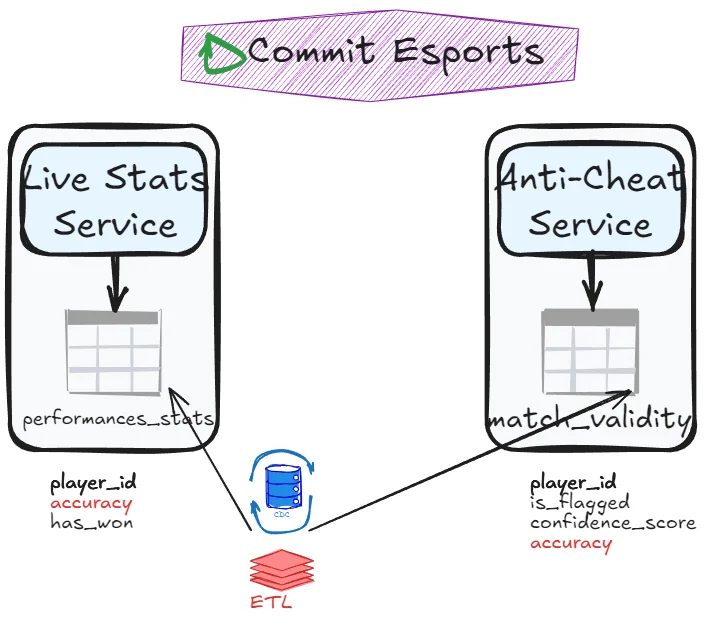
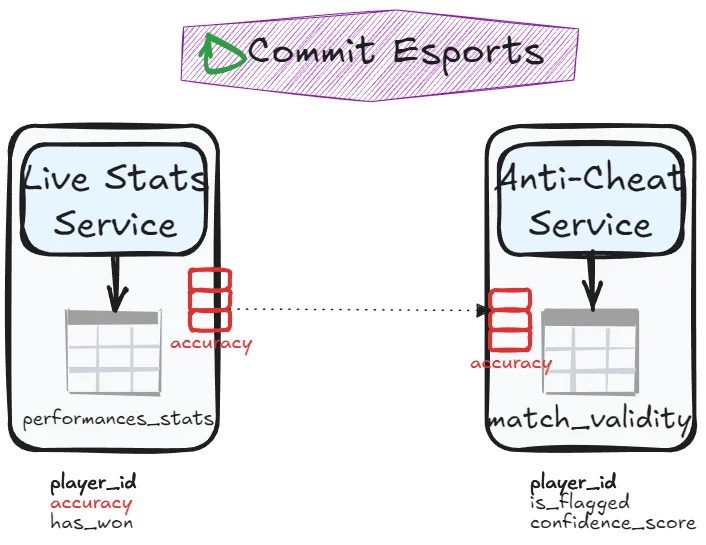
Split columns into separate tables. If one service handles the workload first, it transfers remaining data to the other service. Say match_results table has the following column: player_id, accuracy, has_won, is_flagged, confidence_score. It could be split into a table performance_stats with player_id, accuracy, has_won and another table match_validity with player_id, is_flagged and confidence_score. If the Anti-cheat service still needs read access to accuracy, it can communicates with the live stats service (more on that in next chapter):
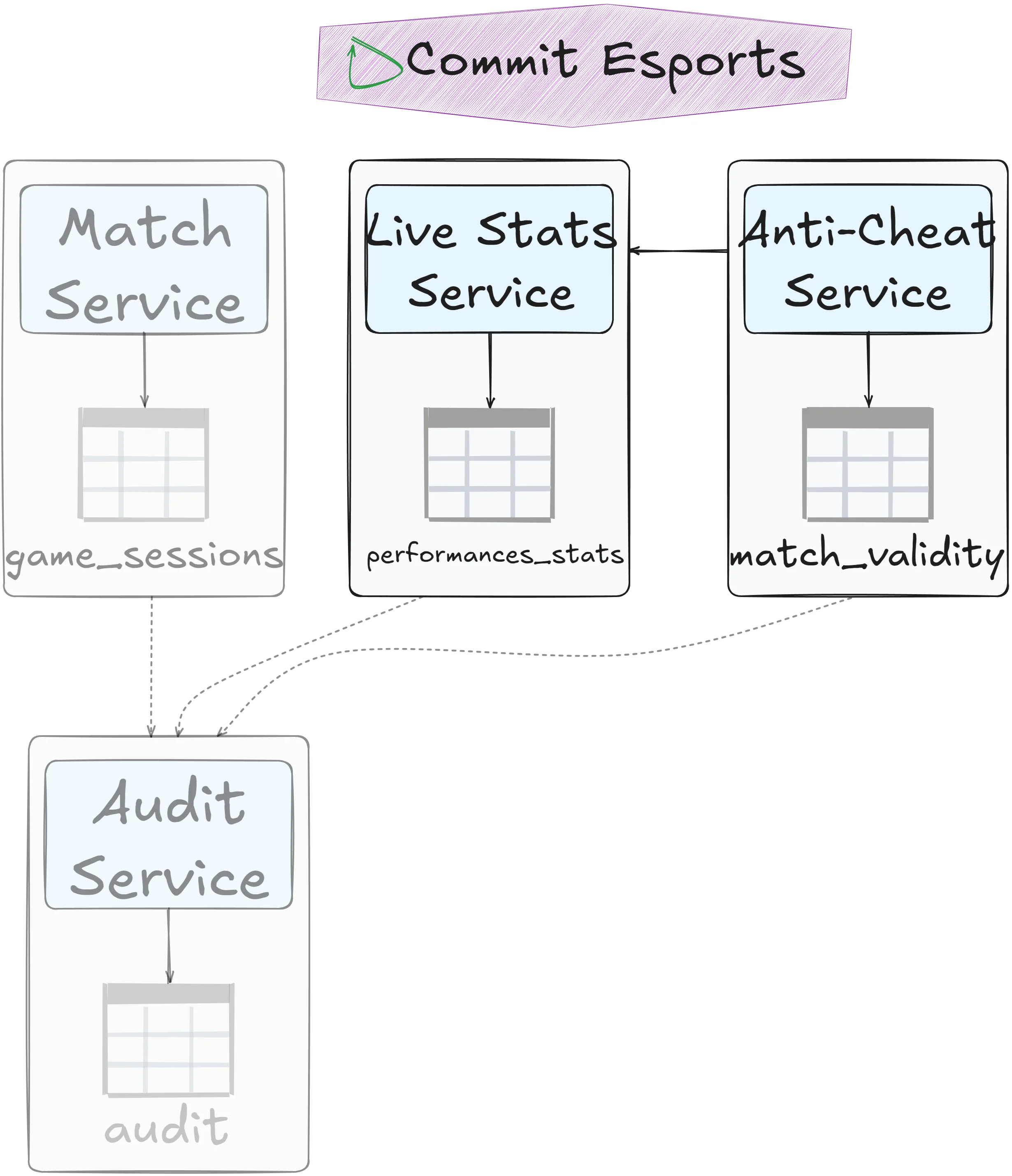
Best when: The table naturally splits along column boundaries.
Data domain
Accept that both services share a bounded context, creating a broader domain:
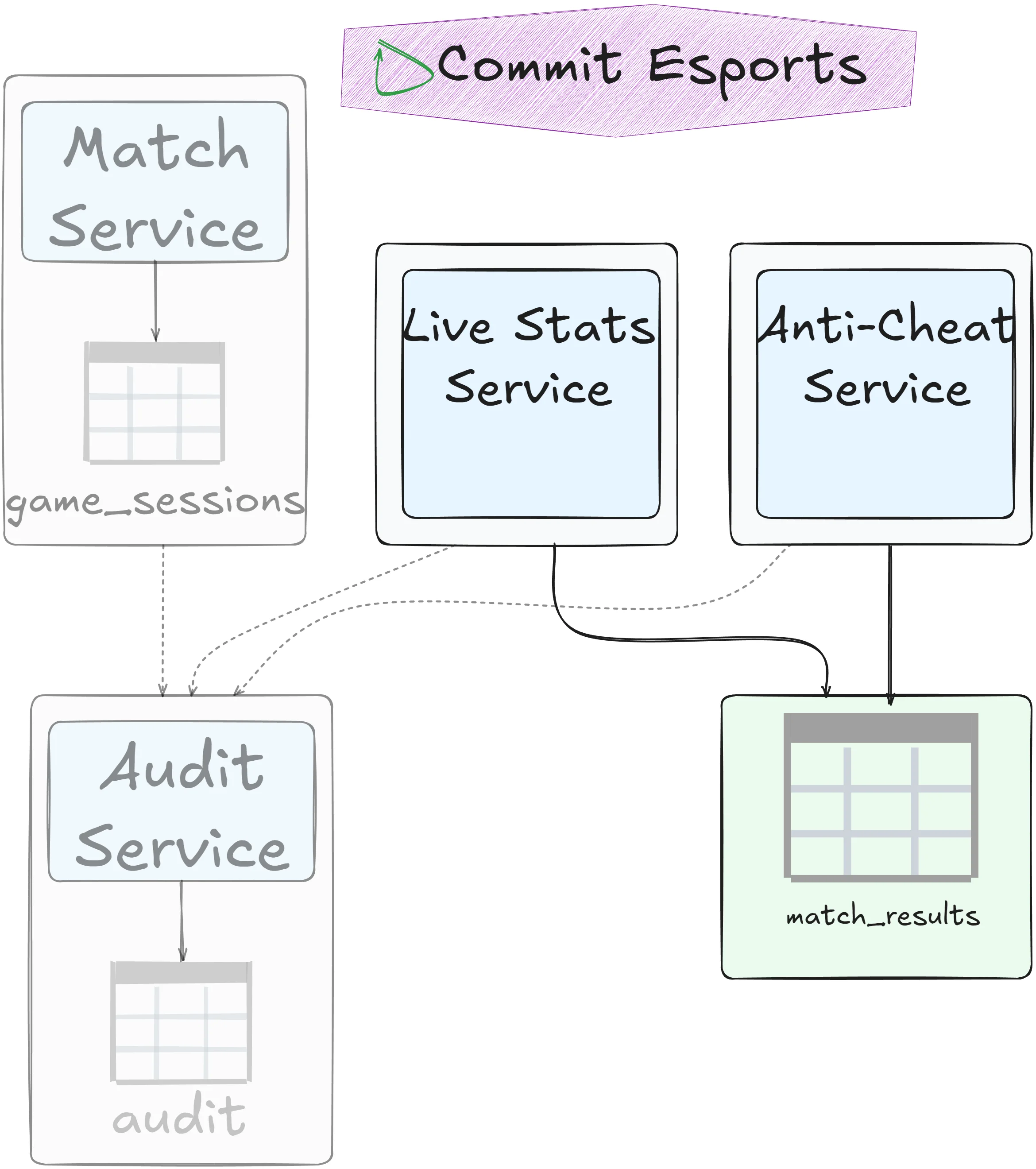
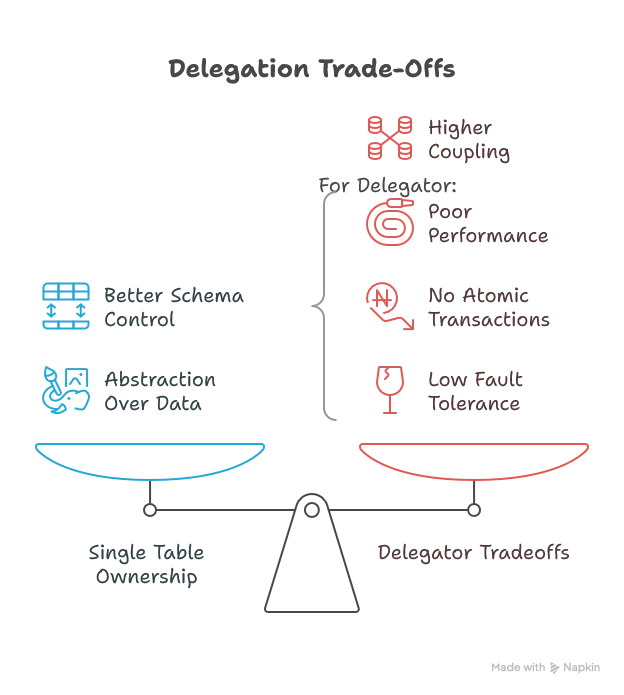
Delegation
One service owns writes (the delegate), while the other (the delegator) communicates to perform updates on its behalf:
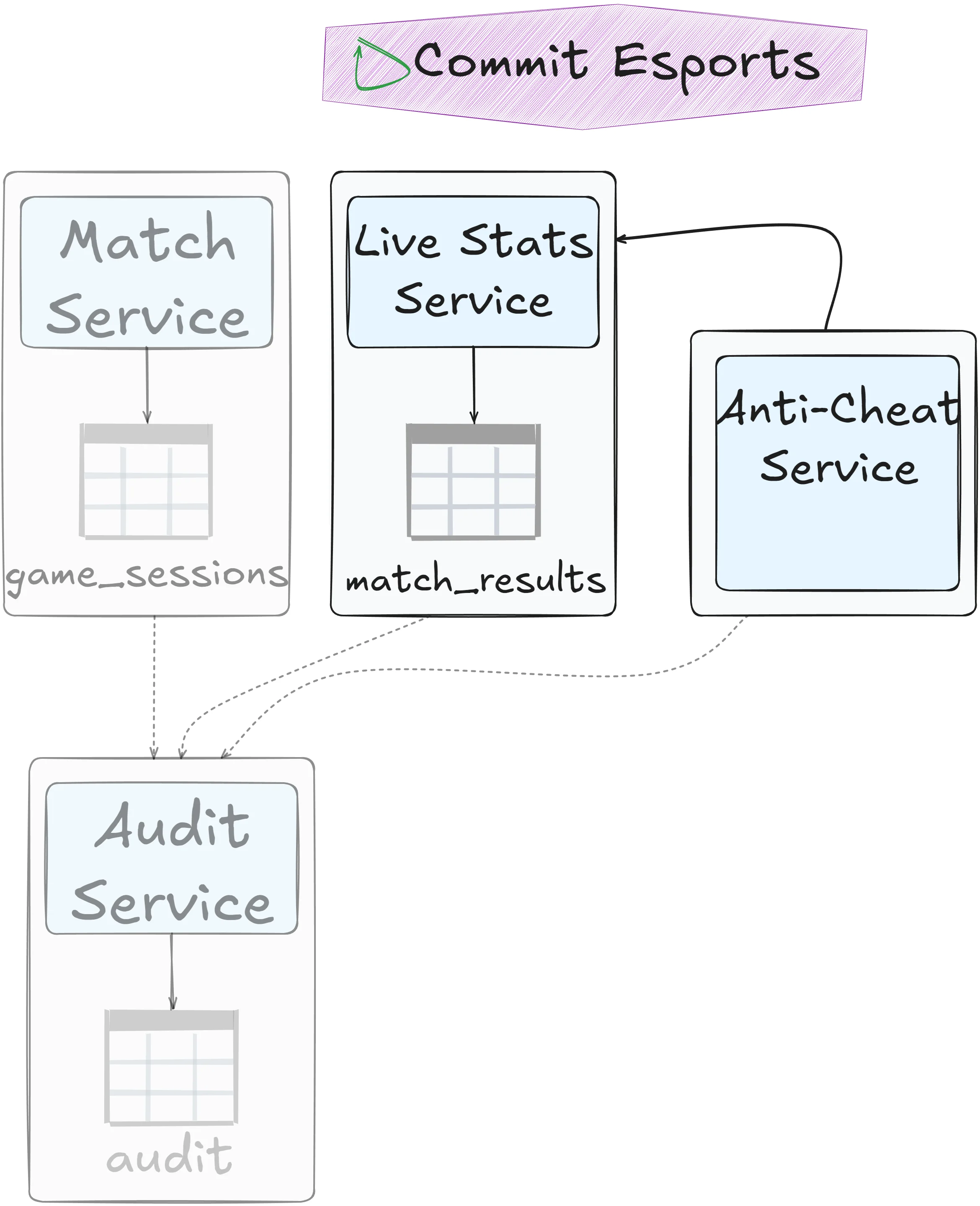
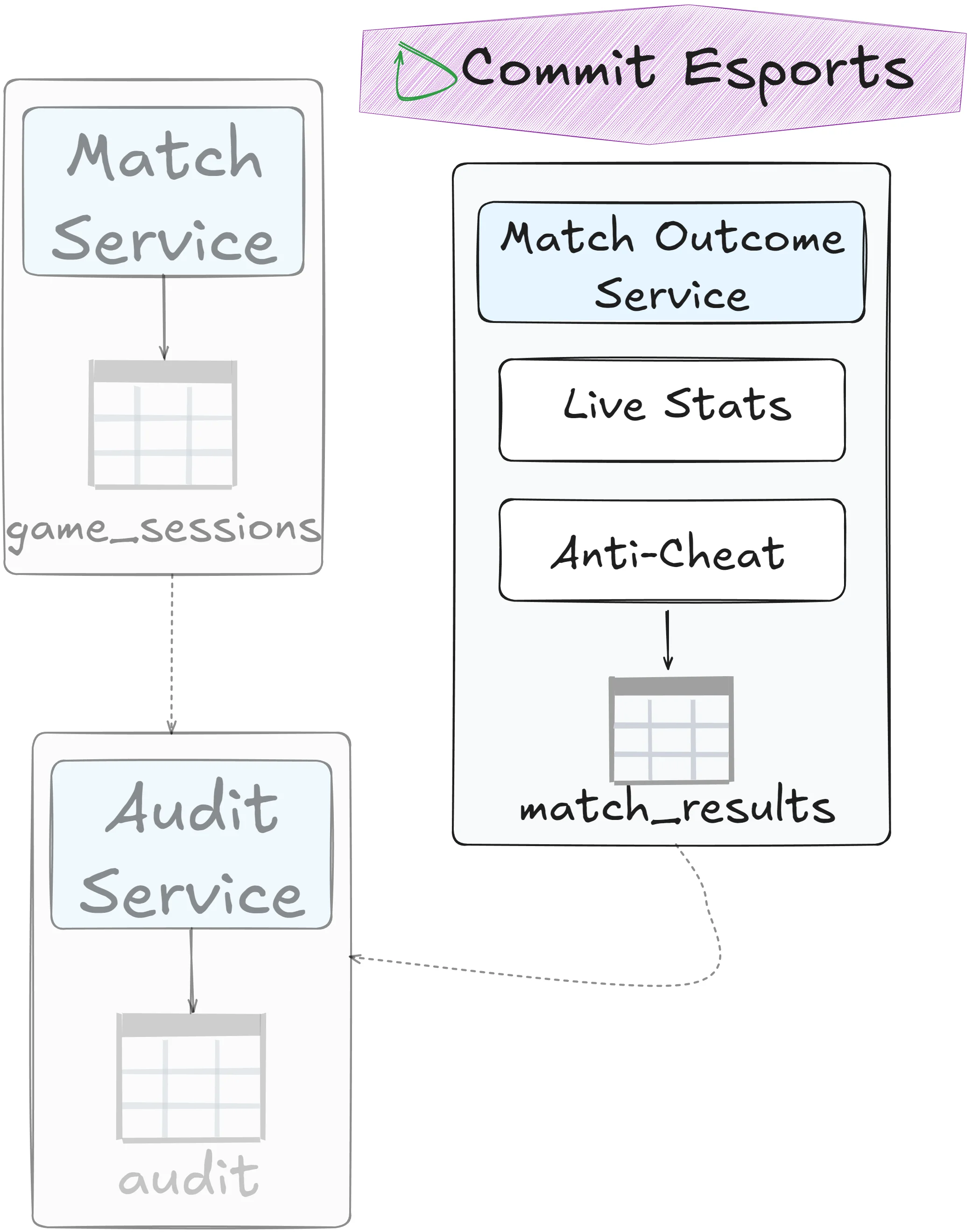
Service consolidation
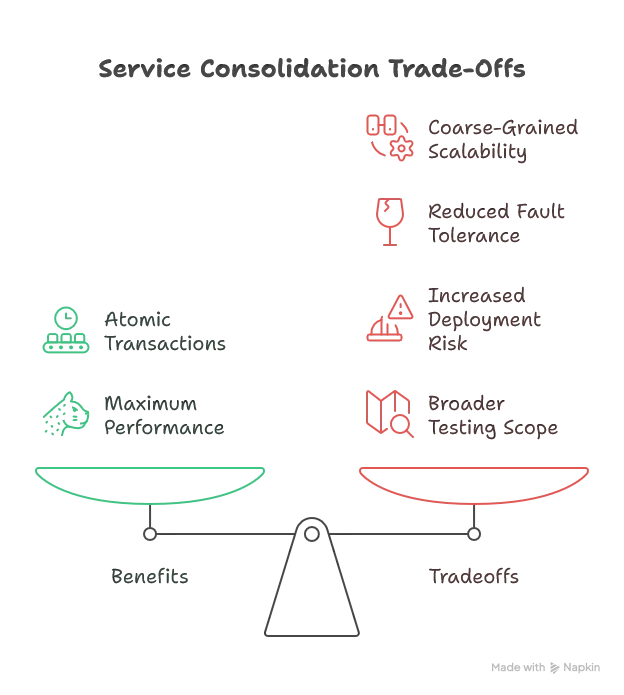
Merge the services back into one:
Data access: The consistency spectrum
The Commit Esports CTO leans back in his chair, a satisfied smile spreading across his face. “Okay, this is great!” he exclaims. “We can assign separate teams to each service! This is going to unlock so much velocity.”
Then he pauses. The smile fades. His eyes narrow as realization hits.
“But wait… we’ve defined who writes to what. That’s only half the battle.” He sits forward, urgency creeping into his voice. “Services still need to read each other’s data. Tournament scheduling needs player statistics. Anti-cheat needs match data. Registration needs payment information. If services can’t talk to each other, what’s the point of splitting them up?”
He’s hit upon the fundamental tension in distributed systems: independence versus integration. You’ve carefully separated your services to achieve autonomy, scalability, and independent deployment. But those same services need to collaborate to deliver business value.
Welcome to the data access problem—where the rubber meets the road in microservices architecture.
Here’s the uncomfortable truth: there’s no perfect solution. Every data access pattern sits somewhere on a spectrum between two competing forces:
- Consistency: How fresh is the data? Can I trust what I’m reading?
- Autonomy: How independent is my service? What happens when dependencies fail?
Think of it as a see-saw. Push for stronger consistency, and you sacrifice autonomy. Prioritize autonomy, and you accept eventual consistency. The art isn’t finding a pattern that eliminates this tension—it’s choosing the right tradeoff for each use case.
Let’s explore five proven patterns, each making different bets on this consistency-autonomy spectrum. As we walk through them, pay attention not just to how they work, but to when you’d choose one over another. Because in the real world, you’ll likely use all of them—just in different parts of your system.
The CTO’s question was the right one. Now let’s give him some answers.
Interservice Communication
Pattern: Services communicate directly to request data from owning services via synchronous API calls.
This is the most intuitive pattern—it’s how we’ve always built systems. Service A needs data? Call Service B. Simple. Direct. Honest about its dependencies.
But here’s the catch: you’re trading autonomy for consistency. When Service B goes down, Service A goes down with it. You’ve created a distributed monolith with extra steps and network latency to boot.
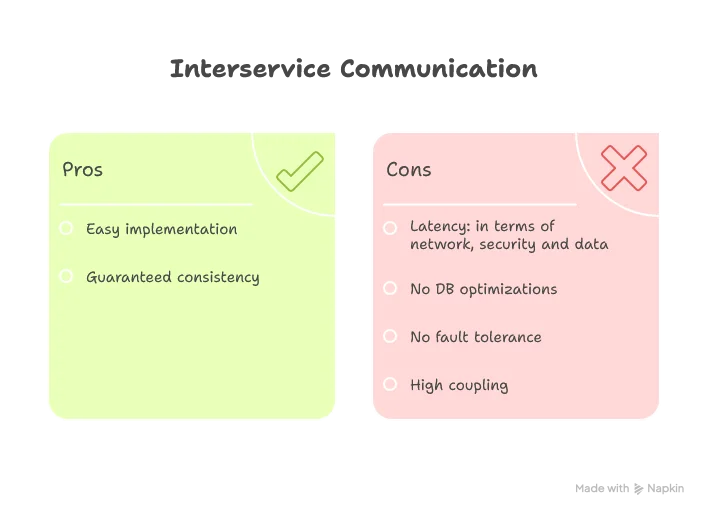
Best for: Low-volume, critical data that must be current. Think payment authorization or user authentication—scenarios where stale data isn’t just wrong, it’s dangerous.
Data Replication
Pattern: Data is replicated from source to target systems through scheduled ETL/batch processes or Change Data Capture (CDC).
Now we swing the other direction. Instead of asking for data when you need it, you copy it ahead of time. Services become self-sufficient—they have their own copy of the data they need.
The consistency sacrifice is obvious: your data is always a bit stale. But the autonomy gain is massive. Your service keeps running even when upstream dependencies fail. You can optimize your local queries without coordinating with other teams. You can even use a different database technology entirely.
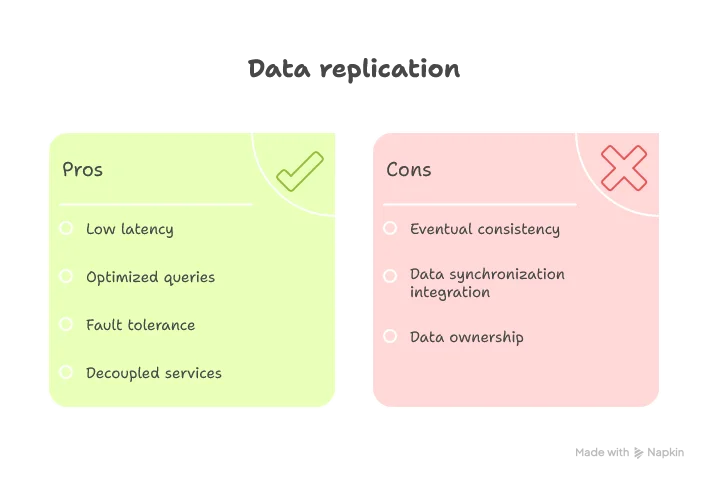
Best for: Analytics, reporting, and high-volume read scenarios where slightly stale data is acceptable. Your dashboard showing “active users this hour” doesn’t need second-by-second precision.
In-Memory Replicated Cache
Pattern: Services maintain local in-memory caches that are synchronized across instances.
This pattern tries to have its cake and eat it too. Keep data in memory for blazing-fast access, but synchronize it across service instances for near-real-time consistency.
It works beautifully—until it doesn’t. The problem is data volume. Every instance of your service holds a complete copy of the cached data. Scale horizontally? Your memory footprint scales linearly too. And those cache updates? They become a chatty nightmare as your cluster grows.
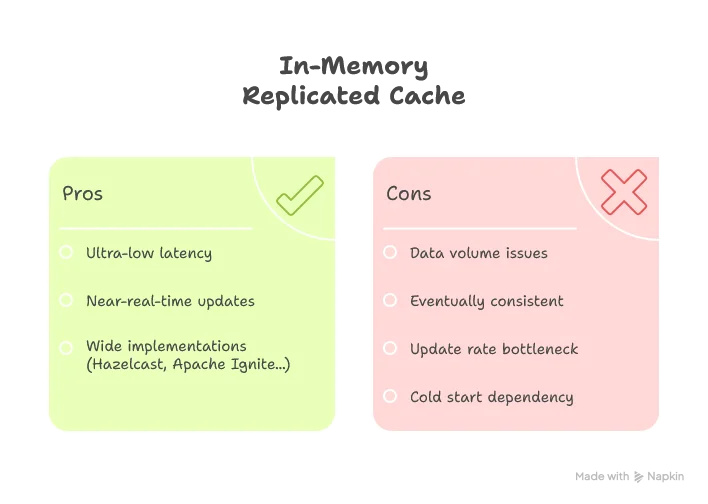
Best for: Reference data, configuration, and frequently accessed small datasets. Think country codes, product categories, or feature flags—data that rarely changes but gets read constantly.
Data Sidecar with Distributed Cache
Pattern: Each service has a dedicated cache sidecar (e.g., Redis) for localized data access.
The sidecar pattern learns from the replicated cache’s mistakes. Instead of duplicating data across service instances, you maintain a single, external cache that all instances share. This dramatically reduces memory footprint and improves horizontal scaling.
You pay for this with an extra network hop—but it’s a local hop to a blazing-fast cache, not a cross-service call through load balancers and security layers.
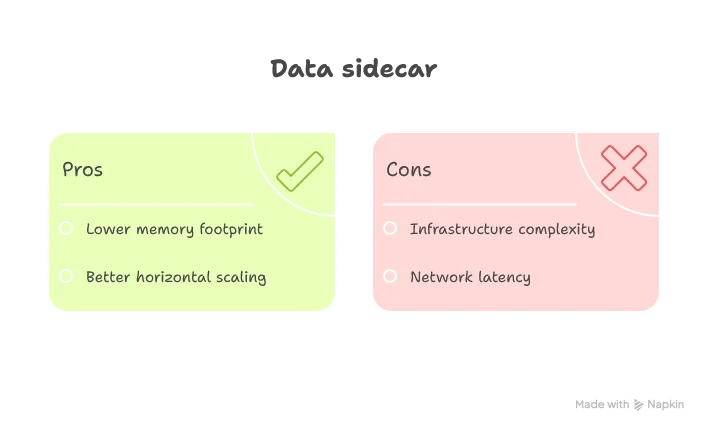
Best for: High-read scenarios with moderate consistency requirements. Session data, shopping carts, frequently accessed user profiles—data that benefits from caching but doesn’t fit the small-dataset constraint of replicated caches.
Data Domain
Pattern: Services own and expose their domain data through well-defined bounded contexts.
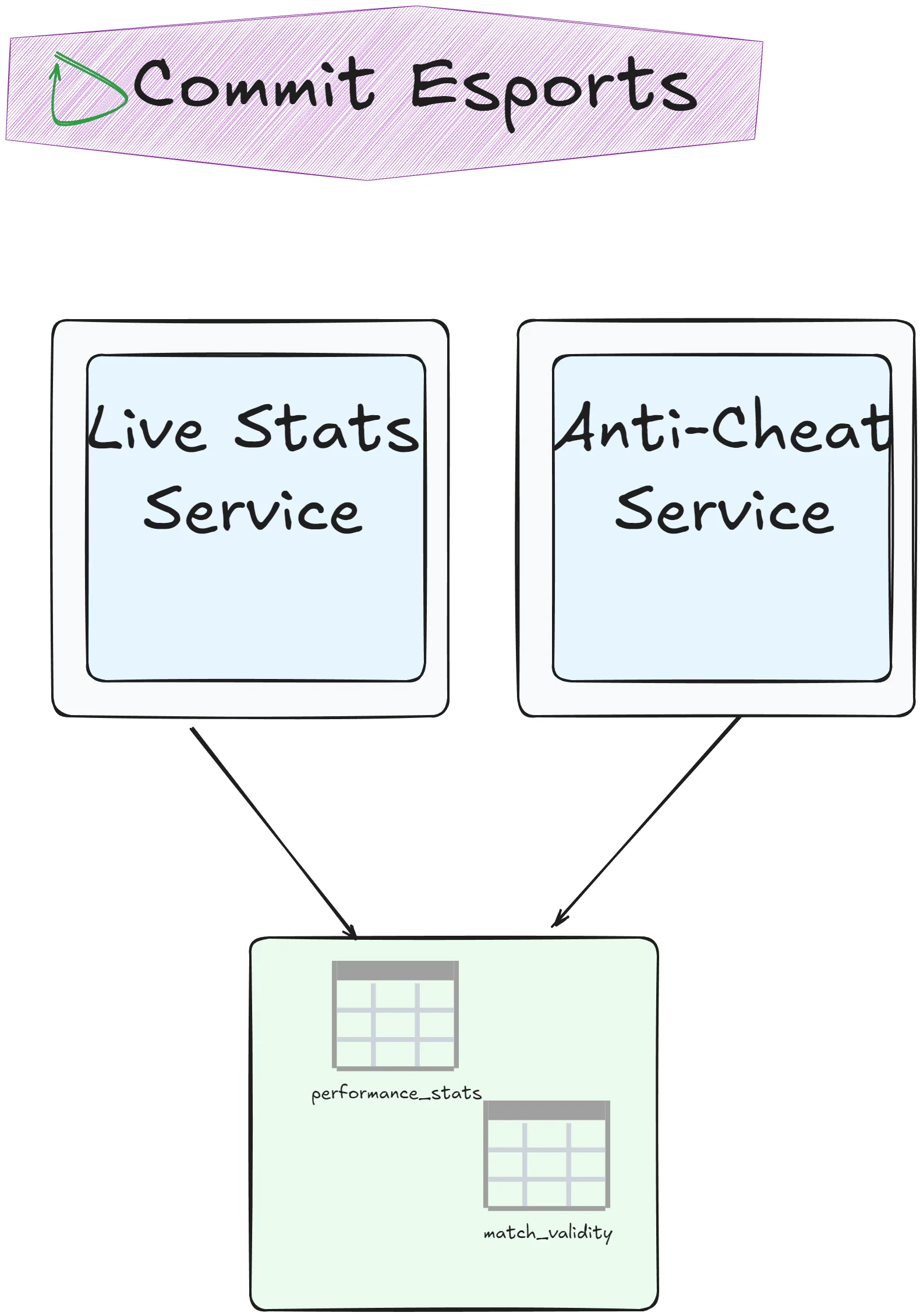
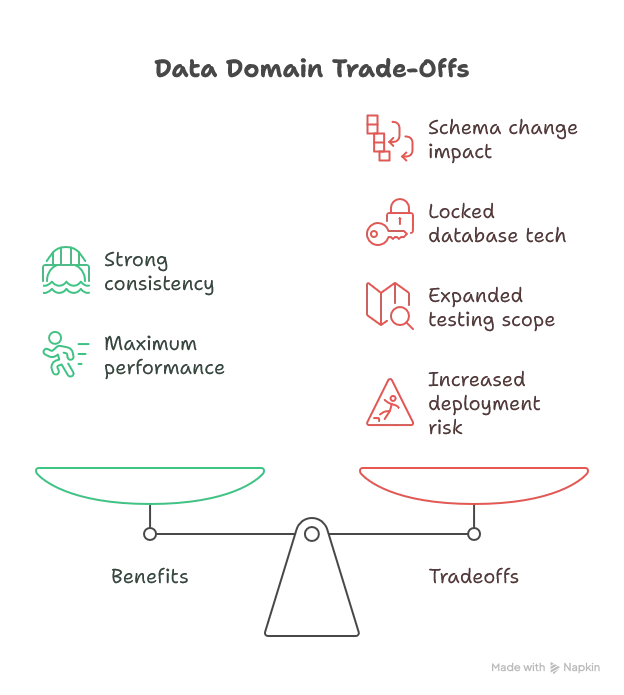
Here’s where we circle back to a controversial idea: maybe some data shouldn’t be split across services at all. The Data Domain pattern acknowledges that certain business capabilities are so tightly coupled that trying to separate them creates more problems than it solves.
Instead of fighting the coupling, you embrace it—but you do it intentionally. You define clear bounded contexts where multiple services can access shared data directly through the database. You maintain service boundaries at the application layer while sharing data infrastructure.
This pattern sits in an interesting middle ground. You get database-level consistency and performance. You avoid the fragility of synchronous service calls. But you sacrifice some autonomy—schema changes require coordination, and you’re locked into the same database technology.
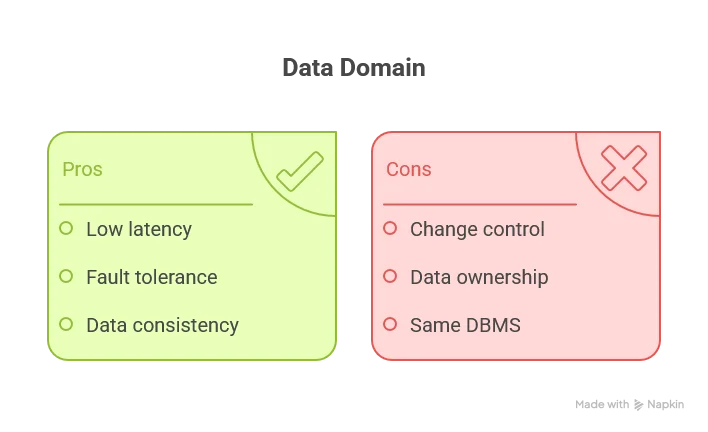
Best for: Modular monoliths and microservices architectures where strong domain boundaries exist but certain operations genuinely need transactional consistency. Order processing with inventory management. User accounts with permissions. Financial transactions with audit logs.
The CTO nods slowly, processing all five patterns. “So there’s no silver bullet,” he says. “We’ll need to use different patterns for different parts of our system.”
Exactly. The key isn’t choosing the right pattern—it’s choosing the right pattern for each specific use case. Your architecture becomes a tapestry of these patterns, each applied where its tradeoffs make sense.
But there’s one more challenge we haven’t tackled yet: what happens when a single business operation needs to update data across multiple services? How do you maintain consistency when no single database can protect you with ACID transactions?
That’s where things get really interesting.
What’s next: Distributed transactions and sagas
So far, we’ve solved the problem of how services access each other’s data for reads. We’ve established clear ownership boundaries and chosen access patterns that balance consistency with autonomy.
But the Commit Esports team is about to discover a harder problem.
“Wait,” the lead developer interrupts, a troubled look crossing her face. “What about writes that span multiple services? When a team registers for a tournament, we need to create the registration record, deduct the entry fee from their account, and update tournament capacity—all atomically. If any step fails, everything should roll back.”
She’s right. In their old monolith, this was simple: wrap it in a database transaction. ACID guarantees took care of everything. But now? The registration service owns registrations. The payment service owns accounts. The tournament service owns capacity. No shared database means no shared transactions.
“So we’re back to calling services synchronously?” another developer asks. “That seems fragile. What if the payment succeeds but then the tournament service times out? We’ve charged them but failed to register them.”
The room falls silent. This is the dark heart of distributed systems: maintaining consistency across service boundaries when operations span multiple data owners.
This is where distributed transactions enter the picture—not necessarily the distributed ACID transactions you might be thinking of, but something more nuanced and practical: sagas.
In our next articles, we’ll dive deep into the world of distributed transactions. We’ll explore:
- Why traditional ACID transactions don’t work in microservices
- The saga pattern and its guarantees
- Eight distinct saga implementation patterns, from the simple to the sophisticated
- How to choose the right saga pattern for your use case
- Practical strategies for handling failures, compensations, and eventual consistency
The Commit Esports team has learned how to split their data. Now they need to learn how to keep it consistent across services. That journey starts with understanding that in distributed systems, consistency isn’t something you get for free—it’s something you design for, pattern by pattern, tradeoff by tradeoff.
See you in the next article, where we’ll tackle the hardest part of microservices architecture head-on.