
Foundation
What is Smart Data Lake Builder?
Smart Data Lake Builder (SDLB) is an open-source framework that simplifies the process of building and maintaining data lakes. It enables data engineers and analysts to define complex data transformations, connections, and workflows using a declarative approach with HOCON (Human-Optimized Config Object Notation) configuration files.
SDLB provides several key benefits:
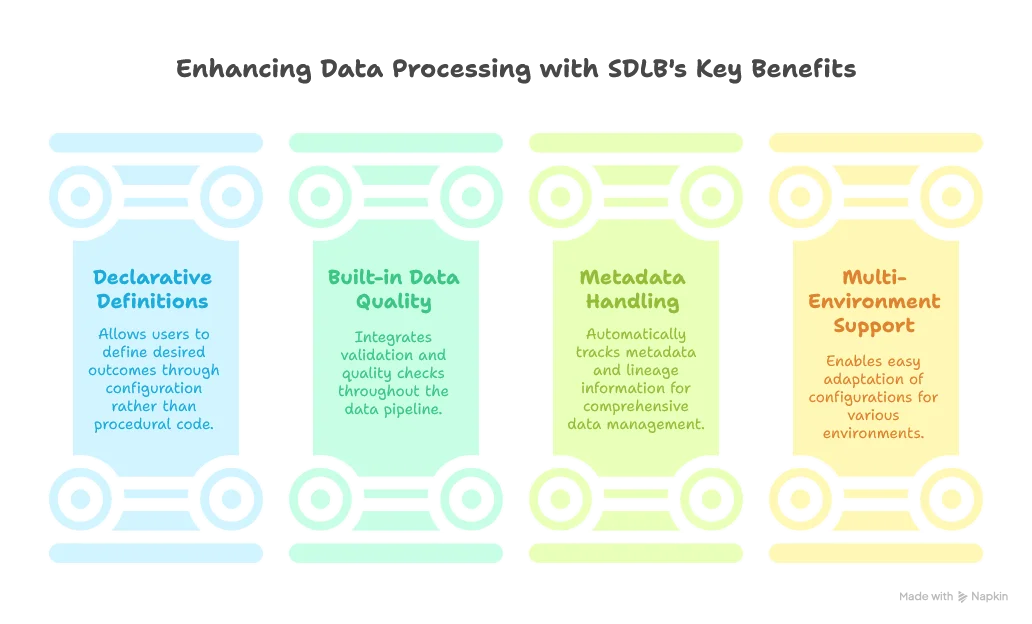
A typical SDLB configuration is written in HOCON and might look like this:
global {
spark-options {
"spark.sql.shuffle.partitions" = 2
}
}
dataObjects {
ext-airports {
type = WebserviceFileDataObject
url = "https://example.com/api/airports"
followRedirects = true
readTimeoutMs=200000
}
stg-airports {
type = CsvFileDataObject
path = "~{id}"
}
}
actions {
download-airports {
type = FileTransferAction
inputId = ext-airports
outputId = stg-airports
metadata {
feed = download
}
}
select-airport-cols {
type = CopyAction
inputId = stg-airports
outputId = int-airports
transformers = [{
type = SQLDfTransformer
code = "select ident, name, latitude_deg, longitude_deg from stg_airports"
}]
metadata {
feed = compute
}
}
}The complexity of these configurations grows quickly with larger data lakes, making robust editor support vital for developer productivity.
The LSP Protocol Explained
The Language Server Protocol (LSP) was created by Microsoft to standardize the communication between code editors and language servers that provide intelligent features. Before LSP, each IDE had to implement language-specific features from scratch, leading to duplicated work and inconsistent experiences across editors.
LSP establishes a JSON-RPC based protocol between:
- The LSP Client: Built into the IDE/editor
- The LSP Server: A standalone process that understands a specific language
The protocol defines standardized messages for capabilities like:
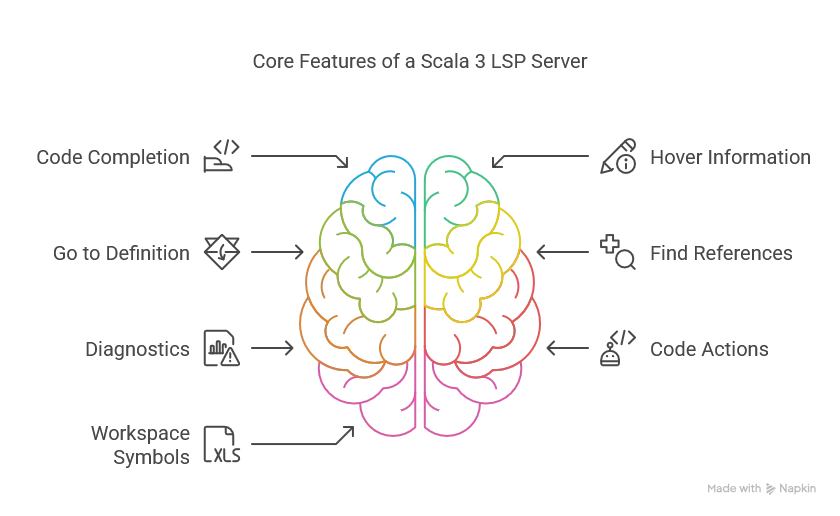
- Code completion: Suggesting code as you type
- Hover information: Showing documentation when hovering over symbols
- Go to definition: Navigating to where a symbol is defined
- Find references: Locating all usages of a symbol
- Diagnostics: Reporting errors and warnings
- Code actions: Offering automated fixes
- Workspace symbols: Finding symbols across multiple files
LSP Communication Flow
The typical flow of LSP communication includes:
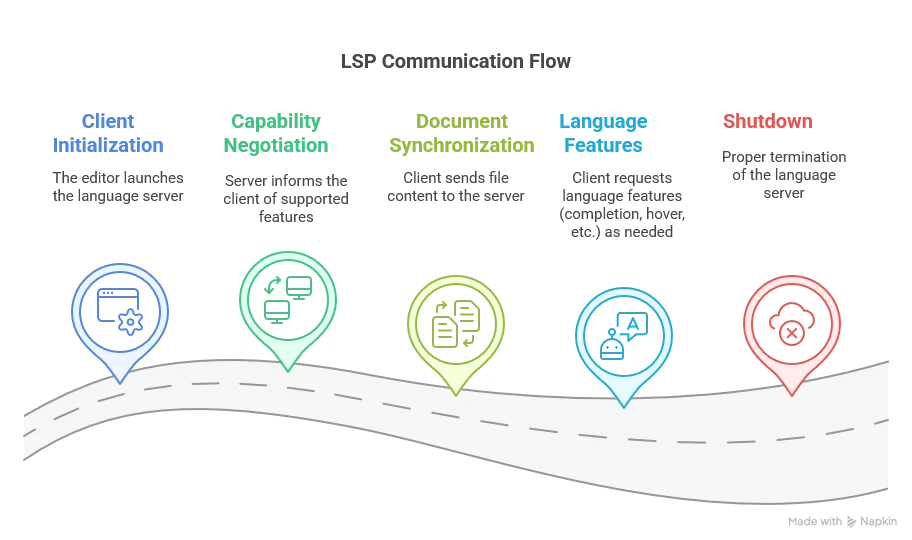
LSP is language-agnostic and editor-agnostic, which is why we can implement the server in any language such as Scala that works with both VS Code and IntelliJ IDEA through different client implementations.
The Global Architecture
The architecture consists of these main components:
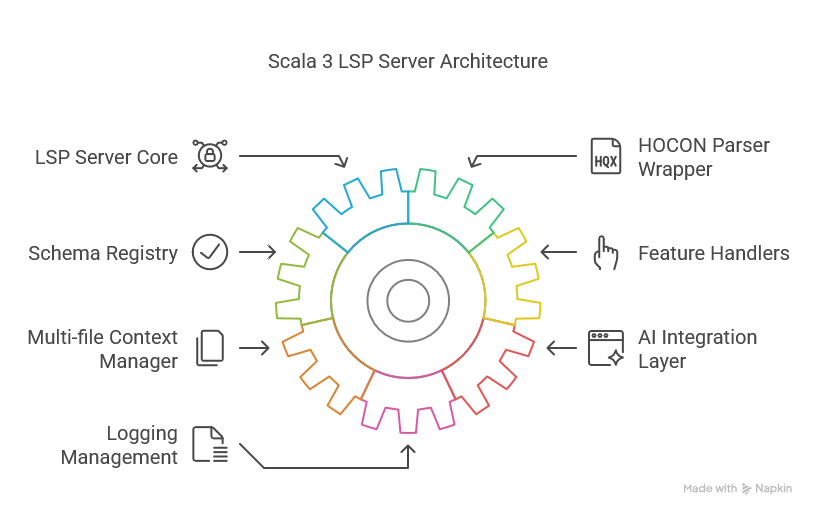
- LSP Server Core
- Handles protocol communication using LSP4J
- Manages document lifecycle (open, change, close)
- Dispatches requests to appropriate handlers
- HOCON Parser Wrapper
- Wraps the Lightbend HOCON parser
- Provides position-aware parsing
- Extracts path context based on cursor position
- Schema Registry
- Loads and validates JSON Schemas for SDLB components
- Provides schema location context given a HOCON path
- Feature Handlers
- Completion Provider: Suggests valid properties and values, enhanced with AI
- Hover Provider: Shows documentation for current element
- Multi-file Context Manager
- Tracks relationships between files
- Implements workspace grouping strategies for different environment scenarios
- Provides cross-file context for suggestions
- AI Integration Layer
- Interfaces with Gemini API
- Applies business rules to AI suggestions
- Optimizes for low-latency responses
- Logging Management
- Provides logs to the client for easier debugging
- Redacts sensitive information, such as the Gemini API Token
- Redirects output stream, as it should be used by LSP4J only for communicating with the client
Server Initialization Flow
When the LSP server starts, it goes through several initialization steps:
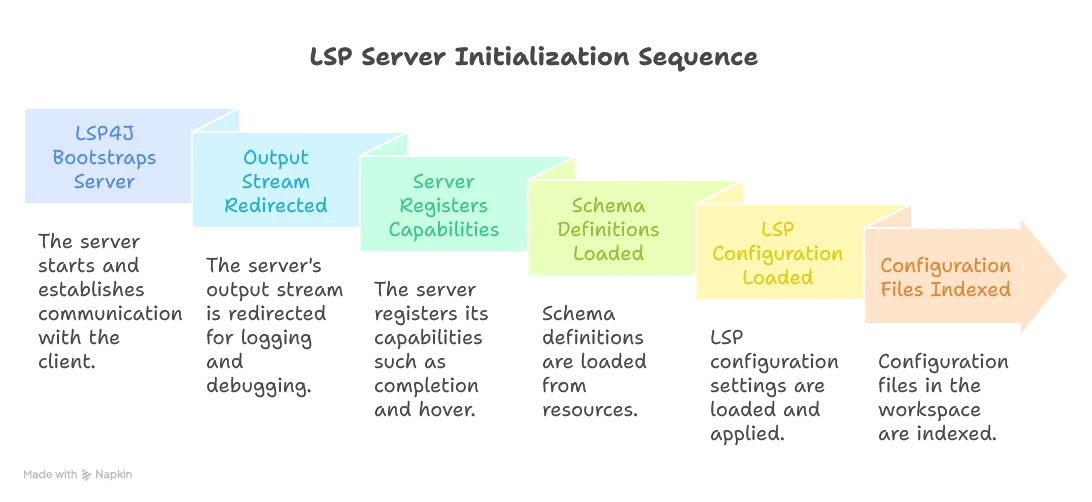
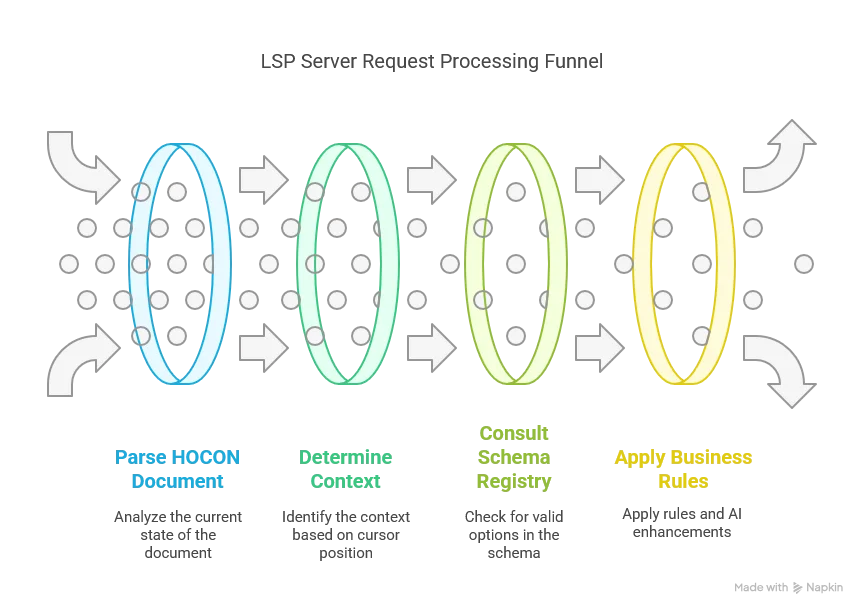
Request Handling Flow
For each user interaction requiring LSP features, the server goes through all of these steps:
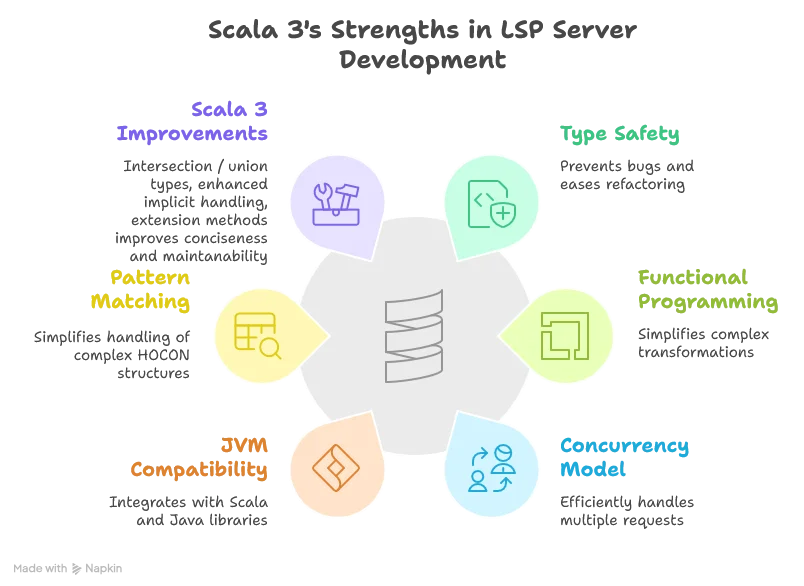
Why Scala 3?
Scala was chosen as our implementation language for several reasons:
Next Steps
In this article, we were introduced to the foundational concepts behind this project.
In the next part, we’ll dive deeper into the HOCON parser wrapper and how we extract path context to provide accurate code assistance.
Stay tuned for “Core Functionality and Logging Management”, where I’ll share the technical details of connecting cursor positions to meaningful path contexts and schema definitions.