
Hocon Processor
Welcome to the third part of this LSP series. After presenting the general architecture of the LSP server in Part 1 and building up the core components along with the logging management system in Part 2, we’ll now dive deeper into the implementation of our custom HOCON parser.
📦 View the source code on GitHub – Explore the complete implementation. Leave a star if you like it!
A Bottom-Up Approach
Until now, we’ve taken a top-down approach to design the system. For this part, we’ll explore the implementation using a bottom-up approach. Our main problems to solve here are:
Understanding the Challenge
For example, let’s say we have the following code, where <caret> is the user’s caret position:
actions {
join-departures-airports {
type = CustomDataFrameAction
inputIds = [stg-departures, int-airports]
outputIds = [btl-departures-arrivals-airports]
transformers = [{
type = SQLDfsTransformer
code = {
btl-connected-airports = "select *"
}},
{
type = SQLDfsTransformer
description = <caret>
}
]
}
}In this complex example, we want to translate the caret position into actions.join-departures-airports.transformers.1.description where:
![]()
Parsing the HOCON Configuration
Luckily, the first challenge of parsing the user’s file into a HOCON config is relatively straightforward. We need to import the corresponding Typesafe library and use their parseString method. First, let’s add the Maven dependency:
<properties>
<maven.compiler.source>21</maven.compiler.source>
<maven.compiler.target>21</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>3.3.4</scala.version>
<lsp4j.version>0.21.0</lsp4j.version>
<typesafe.config.version>1.4.3</typesafe.config.version> <!-- add this line -->
<logback.version>1.4.12</logback.version>
</properties>
(...)
<!-- add this dependency block -->
<dependency>
<groupId>com.typesafe</groupId>
<artifactId>config</artifactId>
<version>${typesafe.config.version}</version>
</dependency>Then let’s define a class that takes the text as a String and returns the Config object:
/**
* Utility class to parse HOCON-formatted files
* Note that this utility class has a restricted scope to context,
* this is because there needs to be consistency between the text given in argument of the methods
* and the text given in the config file, which is not guaranteed if the user of the class is not aware of that.
*/
private[context] object HoconParser:
/**
* Parse the given text
* @param text in hocon format
* @return parsed text in config format
*/
def parse(text: String): Option[Config] =
Try(ConfigFactory.parseString(text)).toOption
val EMPTY_CONFIG: Config = ConfigFactory.parseString("")That’s it! We try to parse the config resiliently and we also define a neutral representation of the config, allowing us to stick to the Flyweight Pattern, optimizing the memory footprint of our application.
Converting Caret Position to Context Path
Now, for converting the caret position into a context path, this is more complex. Unfortunately, the HOCON parser does not provide such a feature (at least not yet). Because it becomes quickly complex, let’s just look at the high-level approach. For the curious, you can find the full implementation here: 📦 View the source code of HoconParser.scala.
def retrieveParentPath(text: String, line: Int, col: Int): List[String] =
@tailrec
def retrievePathHelper(line: Int, col: Int, acc: List[String]): List[String] =
val ((parentLine, parentCol), parentName) = retrieveDirectParent(text, line, col)
val indexIfInList: Option[Int] = findIndexIfInList(text, line, col)
if parentName.isEmpty then acc
else
val newAcc = indexIfInList match
case Some(idx) if idx >= 0 && isParentOutsideArray(text, line, col, parentLine, parentCol) => parentName :: idx.toString :: acc
case _ => parentName :: acc
retrievePathHelper(parentLine, parentCol, newAcc)
retrievePathHelper(line-1, col, List.empty) // Line is 1-basedLet’s examine the key elements of this implementation:
- We use the Scala
@tailrecannotation. This ensures our implementation is tail-recursive, which means the Scala compiler can optimize our recursive implementation into a for-loop, making it faster by eliminating recursive call overhead. - There is special handling if the current object is in a list. In that case, we also append the index in the parent path.
The remaining code is quite complex because it needs to handle multiple edge cases, with the main ones being:
- Ignoring comment lines, or parts of lines if comments are inserted in the same line
- Flattening multi-line string values, as they don’t match with the origin line of the HOCON config otherwise
- Using multiple regex patterns to understand how deep we are in lists and objects, and how the split between a key and value is done (HOCON allows multiple ways of splitting keys and values)
Building the Context Classes
Now we can build our context case classes. The architecture uses two layers: TextContext handles the raw text and HOCON parsing, while SDLBContext adds cursor position awareness and path extraction:
case class TextContext private (originalText: String, configText: String, rootConfig: Config) extends SDLBLogger {
def update(newText: String): TextContext = this match
case EMPTY_TEXT_CONTEXT => TextContext.create(newText)
case _ => updateContext(newText)
private def updateContext(newText: String) =
val newConfigText = MultiLineTransformer.flattenMultiLines(newText) // Not so important for now. Could be omitted
val newConfigOption = HoconParser.parse(newConfigText)
val newConfig = newConfigOption.getOrElse(HoconParser.EMPTY_CONFIG)
if newConfig == HoconParser.EMPTY_CONFIG then
copy(originalText=newText)
else
copy(originalText=newText, configText=newConfigText, rootConfig=newConfig)
}
object TextContext {
val EMPTY_TEXT_CONTEXT: TextContext = new TextContext("", "", HoconParser.EMPTY_CONFIG)
def create(originalText: String): TextContext =
val configText = MultiLineTransformer.flattenMultiLines(originalText)
val config = HoconParser.parse(configText).getOrElse(HoconParser.EMPTY_CONFIG)
TextContext(originalText, configText, config)
}case class SDLBContext private(textContext: TextContext, parentPath: List[String], word: String) {
export textContext.rootConfig
def withText(newText: String): SDLBContext = copy(textContext = textContext.update(newText))
def withCaretPosition(originalLine: Int, originalCol: Int): SDLBContext =
val TextContext(originalText, configText, config) = textContext
if originalLine <= 0 || originalLine > originalText.count(_ == '\n') + 1 || originalCol < 0 then this else
val (newLine, newCol) = MultiLineTransformer.computeCorrectedPosition(originalText, originalLine, originalCol)
val word = HoconParser.retrieveWordAtPosition(configText, newLine, newCol)
val parentPath = HoconParser.retrieveParentPath(configText, newLine, newCol)
copy(parentPath = parentPath, word = word)
def getParentContext: Option[ConfigValue] =
@tailrec
def findParentContext(currentConfig: ConfigValue, remainingPath: List[String]): Option[ConfigValue] = remainingPath match
case Nil => Some(currentConfig)
case path::newRemainingPath => currentConfig match
case asConfigObject: ConfigObject => findParentContext(asConfigObject.get(path), newRemainingPath)
case asConfigList: ConfigList => findParentContext(asConfigList.get(path.toInt), newRemainingPath)
case _ => None
findParentContext(textContext.rootConfig.root(), parentPath)
}
object SDLBContext {
val EMPTY_CONTEXT: SDLBContext = SDLBContext(EMPTY_TEXT_CONTEXT, List(), "")
def fromText(originalText: String): SDLBContext =
SDLBContext(TextContext.create(originalText), List(), "")
def fromText(originalText: String): SDLBContext = fromText("", originalText, Map.empty)
}What stands out in TextContext:
- The case class is fully immutable, making the code more robust
- Use of
privateincase class TextContext private (uri: String, .... This allows us to completely control how the object is instantiated, making its default constructor private - Use of the
copymethod. Because case classes are immutable by default and by design, we are encouraged to create a new instance with the updated values rather than mutating the instance.copyis a built-in method of case classes allowing us to do this efficiently - Use of a Companion Object (
object TextContext). This is the entry point for the users of this case class to be able to create a newTextContext. Then users of this class need to use theupdatemethod to ensure all the updating handling is done correctly by us
Building Resilience Into the Parser
I talked about having a resilient system for parsing user files. This is crucial, as a user currently editing the text will trigger an update of the content at every single character change. Did you spot how we did the trick? This is the very important code here:
if newConfig == HoconParser.EMPTY_CONFIG then
copy(originalText=newText)If the user enters an invalid state, which happens very often during editing, we just keep track of the last valid state by not updating the configText and the rootConfig. That’s it!
Understanding SDLBContext
Most Scala 3 features are reused from TextContext, but there are also some new features we rely on here in SDLBContext:
val TextContext(originalText, configText, config) = textContextScala 3 allows us to deconstruct a case class easily, avoiding us to write verbose code like this:
val originalText = textContext.originalText
val configText = textContext.configText
val config = textContext.configexport textContext.rootConfigThis is a practical shorthand way of writing:
def rootConfig: Config = textContext.rootConfigThe added value is clearer if we needed to bridge multiple values or methods from TextContext. We could have used export textContext.{originalText, rootConfig} for example. This gives us better maintenance, conciseness, and encourages us to follow the Law of Demeter, aka the Principle of Least Knowledge.
Also, we took the opportunity to define here the algorithm translating the parent path into a ConfigValue in def getParentContext: Option[ConfigValue].
Tracking Document Changes
To close the implementation, we now just need to keep track of every user’s file contents in our TextDocumentService and listen to textDocument/didChange events, given to us by the didChange method of LSP4J. In SmartDataLakeTextDocumentService:
private var uriToContexts: Map[String, SDLBContext] = Map.empty
override def didChange(didChangeTextDocumentParams: DidChangeTextDocumentParams): Unit =
val newText: String = Option(didChangeTextDocumentParams.getContentChanges).flatMap(_.toScala.headOption).map(_.getText).getOrElse("")
val context = uriToContexts.get(uri).getOrElse(SDLBContext.EMPTY_CONTEXT)
uriToContexts = uriToContexts.updated(uri, context.withText(newText))Implementing Completion Support
Also, we can start a part of the implementation of the very important textDocument/completion event, given to us through the completion method:
override def completion(params: CompletionParams): CompletableFuture[messages.Either[util.List[CompletionItem], CompletionList]] = Future {
val uri = params.getTextDocument.getUri
val context = uriToContexts(uri)
val caretContext = context.withCaretPosition(params.getPosition.getLine+1, params.getPosition.getCharacter)
//To be defined later
//val completionItems: List[CompletionItem] = completionEngine.generateCompletionItems(caretContext)
Left(completionItems.asJava).asJava
}.asJavaNote that:
- The
asJavawrappers could be omitted in Scala 3 with the use of implicit conversions, but I personally like to see exactly where I’m doing the conversions. caretContexts are actually never stored. They are only computed when the LSP client requests completions.
If you look at the current code, everything shown here is actually out-of-date, because we’ll see in a future post how to handle multiple files context-awareness and workspace management.
Conclusion
In this article, we’ve built the foundation of our HOCON parser with context awareness - a critical component that enables our LSP server to provide intelligent code assistance. We’ve covered:
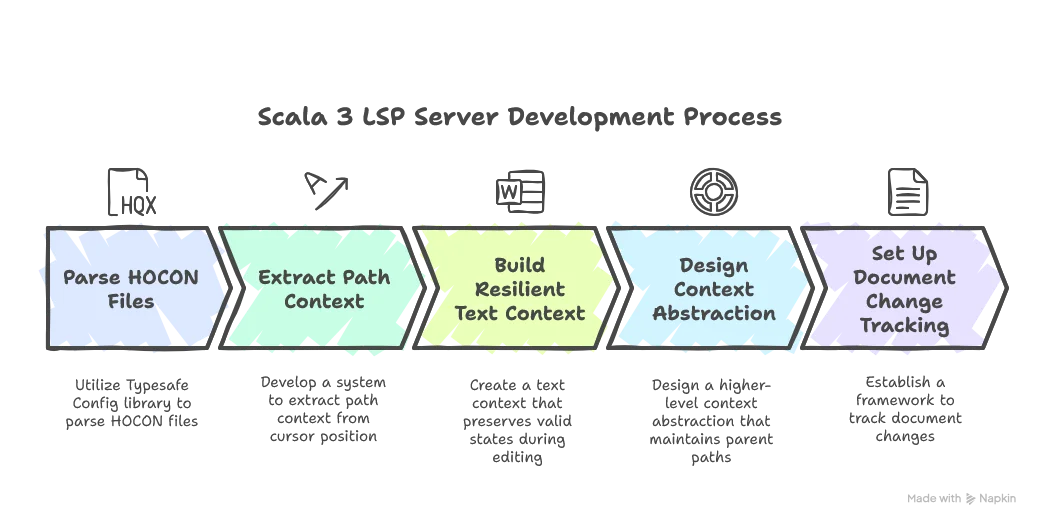
The clever use of Scala 3 features like export, pattern matching, private constructors with companion objects, and tailrec optimization makes our code both robust and concise.
In the next article, we’ll explore how to use this context information to implement code completion and hover information based on JSON schema definitions.
Stay tuned for “Implementing a Schema Reader for Intelligent Code Suggestions” where we’ll leverage our context-aware parser to traverse our Json schema.